publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
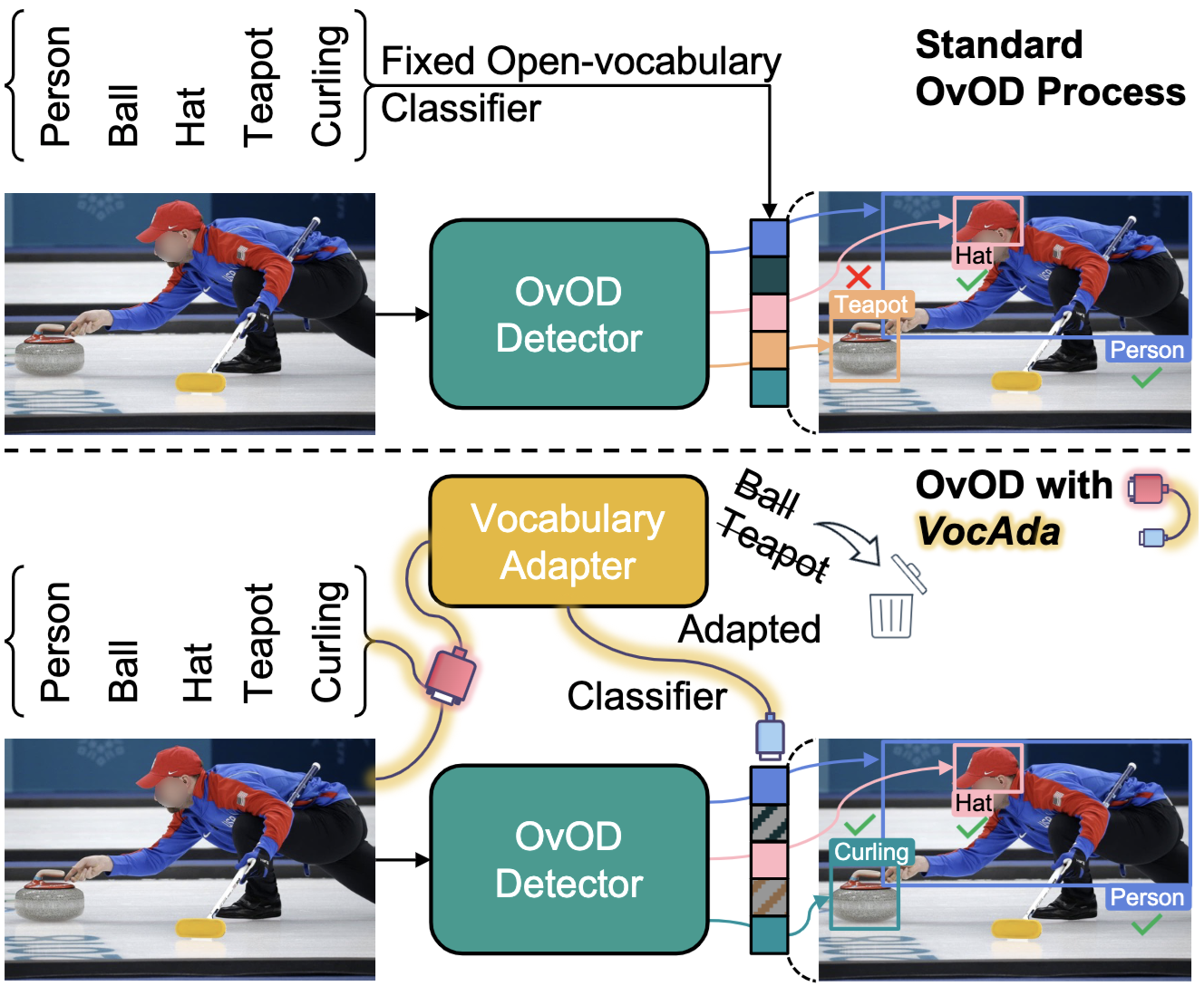 Test-time Vocabulary Adaptation for Language-driven Object DetectionMingxuan Liu , Tayler L. Hayes , Massimiliano Mancini, and 3 more authorsIn IEEE International Conference on Image Processing (ICIP) , 2025
Test-time Vocabulary Adaptation for Language-driven Object DetectionMingxuan Liu , Tayler L. Hayes , Massimiliano Mancini, and 3 more authorsIn IEEE International Conference on Image Processing (ICIP) , 2025Open-vocabulary object detection models allow users to freely specify a class vocabulary in natural language at test time, guiding the detection of desired objects. However, vocabularies can be overly broad or even mis-specified, hampering the overall performance of the detector. In this work, we propose a plug-and-play Vocabulary Adapter (VocAda) to refine the user-defined vocabulary, automatically tailoring it to categories that are relevant for a given image. VocAda does not require any training, it operates at inference time in three steps: i) it uses an image captionner to describe visible objects, ii) it parses nouns from those captions, and iii) it selects relevant classes from the user-defined vocabulary, discarding irrelevant ones. Experiments on COCO and Objects365 with three state-of-the-art detectors show that VocAda consistently improves performance, proving its versatility. The code is open source.
@inproceedings{liu2025test, title = {Test-time Vocabulary Adaptation for Language-driven Object Detection}, author = {Liu, Mingxuan and Hayes, Tayler L. and Mancini, Massimiliano and Ricci, Elisa and Volpi, Riccardo and Csurka, Gabriela}, booktitle = {IEEE International Conference on Image Processing (ICIP)}, year = {2025}, } -
 Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language ModelsDavide Berasi , Matteo Farina , Massimiliano Mancini, and 2 more authorsProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language ModelsDavide Berasi , Matteo Farina , Massimiliano Mancini, and 2 more authorsProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025Vision-Language Models (VLMs) learn a shared feature space for text and images, enabling the comparison of inputs of different modalities. While prior works demonstrated that VLMs organize natural language representations into regular structures encoding composite meanings, it remains unclear if compositional patterns also emerge in the visual embedding space. In this work, we investigate compositionality in the image domain, where the analysis of compositional properties is challenged by noise and sparsity of visual data. We address these problems and propose a framework, called Geodesically Decomposable Embeddings (GDE), that approximates image representations with geometry-aware compositional structures in the latent space. We demonstrate that visual embeddings of pre-trained VLMs exhibit a compositional arrangement, and evaluate the effectiveness of this property in the tasks of compositional classification and group robustness. GDE achieves stronger performance in compositional classification compared to its counterpart method that assumes linear geometry of the latent space. Notably, it is particularly effective for group robustness, where we achieve higher results than task-specific solutions. Our results indicate that VLMs can automatically develop a human-like form of compositional reasoning in the visual domain, making their underlying processes more interpretable.
@article{berasi2025not, title = {Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models}, author = {Berasi, Davide and Farina, Matteo and Mancini, Massimiliano and Ricci, Elisa and Strisciuglio, Nicola}, journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2025}, } -
 Compositional Caching for Training-free Open-vocabulary Attribute DetectionMarco Garosi , Alessandro Conti , Gaowen Liu , and 2 more authorsIn , 2025
Compositional Caching for Training-free Open-vocabulary Attribute DetectionMarco Garosi , Alessandro Conti , Gaowen Liu , and 2 more authorsIn , 2025Attribute detection is crucial for many computer vision tasks, as it enables systems to describe properties such as color, texture, and material. Current approaches often rely on labor-intensive annotation processes which are inherently limited: objects can be described at an arbitrary level of detail (eg, color vs. color shades), leading to ambiguities when the annotators are not instructed carefully. Furthermore, they operate within a predefined set of attributes, reducing scalability and adaptability to unforeseen downstream applications. We present Compositional Caching (ComCa), a training-free method for open-vocabulary attribute detection that overcomes these constraints. ComCa requires only the list of target attributes and objects as input, using them to populate an auxiliary cache of images by leveraging web-scale databases and Large Language Models to determine attribute-object compatibility. To account for the compositional nature of attributes, cache images receive soft attribute labels. Those are aggregated at inference time based on the similarity between the input and cache images, refining the predictions of underlying Vision-Language Models (VLMs). Importantly, our approach is model-agnostic, compatible with various VLMs. Experiments on public datasets demonstrate that ComCa significantly outperforms zero-shot and cache-based baselines, competing with recent training-based methods, proving that a carefully designed training-free approach can successfully address open-vocabulary attribute detection.
@inproceedings{garosi2025comca, title = {Compositional Caching for Training-free Open-vocabulary Attribute Detection}, author = {Garosi, Marco and Conti, Alessandro and Liu, Gaowen and Ricci, Elisa and Mancini, Massimiliano}, journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2025}, } -
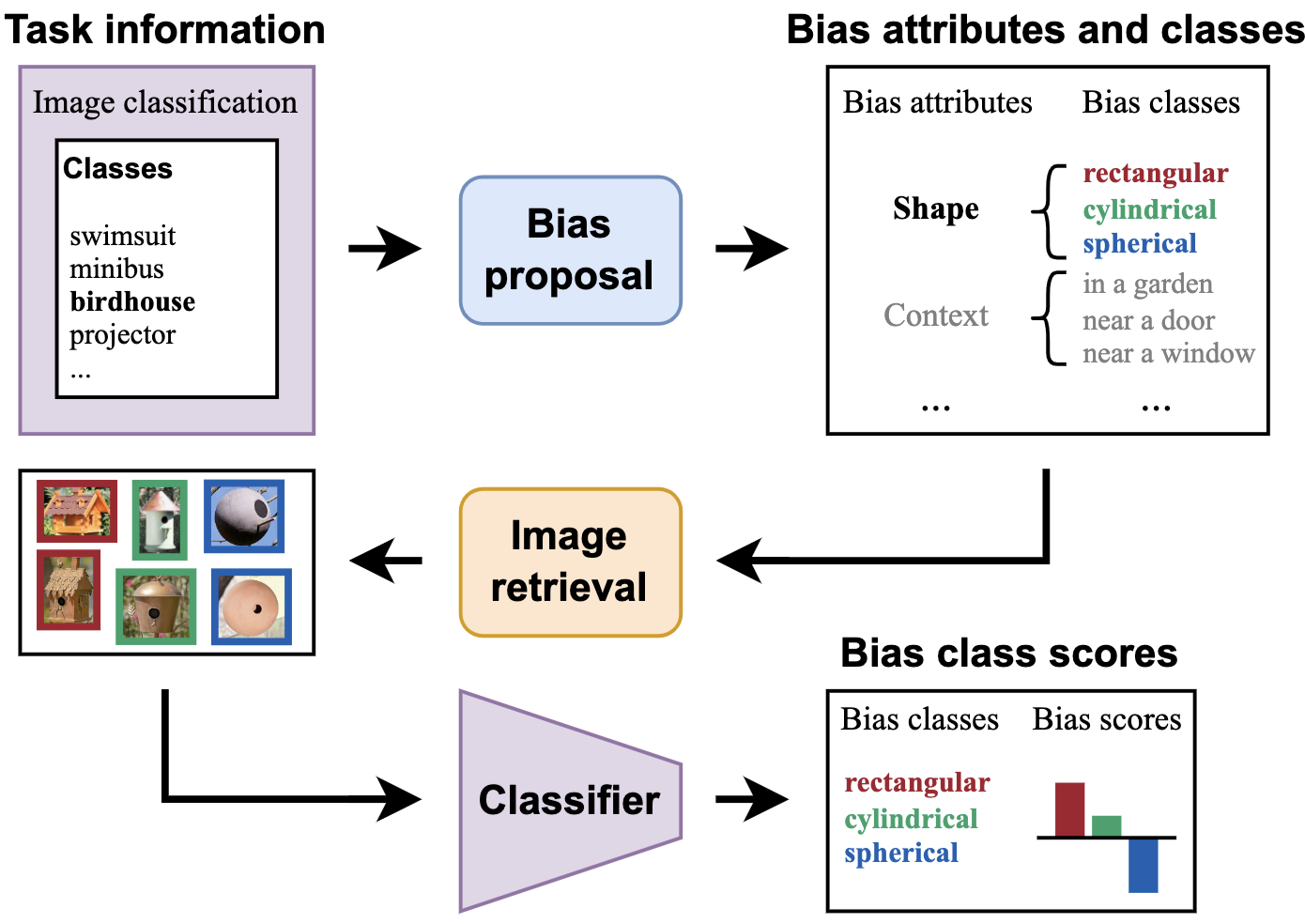 Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual ClassifiersQuentin Guimard , Moreno D’Incà , Elia Peruzzo , and 2 more authorsProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual ClassifiersQuentin Guimard , Moreno D’Incà , Elia Peruzzo , and 2 more authorsProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025A person downloading a pre-trained model from the web should be aware of its biases. Existing approaches for bias identification rely on datasets containing labels for the task of interest, something that a non-expert may not have access to, or may not have the necessary resources to collect: this greatly limits the number of tasks where model biases can be identified. In this work, we present Classifier-to-Bias (C2B), the first bias discovery framework that works without access to any labeled data: it only relies on a textual description of the classification task to identify biases in the target classification model. This description is fed to a large language model to generate bias proposals and corresponding captions depicting biases together with task-specific target labels. A retrieval model collects images for those captions, which are then used to assess the accuracy of the model wrt the given biases. C2B is training-free, does not require any annotations, has no constraints on the list of biases, and can be applied to any pre-trained model on any classification task. Experiments on two publicly available datasets show that C2B discovers biases beyond those of the original datasets and outperforms a recent state-of-the-art bias detection baseline that relies on task-specific annotations, being a promising first step toward addressing task-agnostic unsupervised bias detection.
@article{guimard2025c2b, title = {Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual Classifiers}, author = {Guimard, Quentin and D'Incà, Moreno and Peruzzo, Elia and Mancini, Massimiliano and Ricci, Elisa}, journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2025}, } -
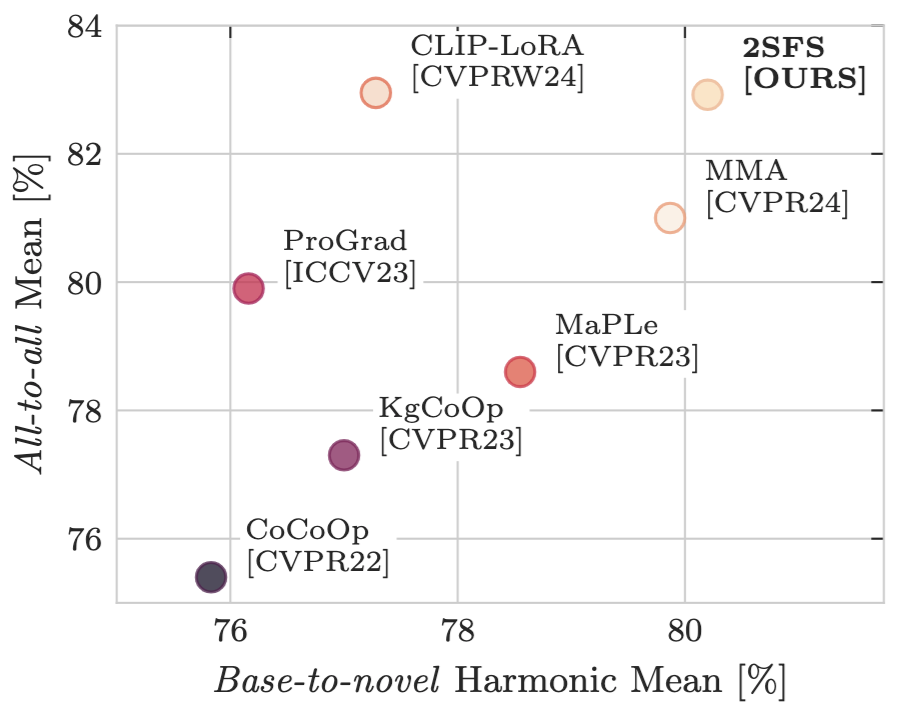 Rethinking Few-Shot Adaptation of Vision-Language Models in Two StagesMatteo Farina , Massimiliano Mancini, Giovanni Iacca , and 1 more authorProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
Rethinking Few-Shot Adaptation of Vision-Language Models in Two StagesMatteo Farina , Massimiliano Mancini, Giovanni Iacca , and 1 more authorProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025An old-school recipe for training a classifier is to (i) learn a good feature extractor and (ii) optimize a linear layer atop. When only a handful of samples are available per category, as in Few-Shot Adaptation (FSA), data are insufficient to fit a large number of parameters, rendering the above impractical. This is especially true with large pre-trained Vision-Language Models (VLMs), which motivated successful research at the intersection of Parameter-Efficient Fine-tuning (PEFT) and FSA. In this work, we start by analyzing the learning dynamics of PEFT techniques when trained on few-shot data from only a subset of categories, referred to as the "base" classes. We show that such dynamics naturally splits into two distinct phases: (i) task-level feature extraction and (ii) specialization to the available concepts. To accommodate this dynamic, we then depart from prompt- or adapter-based methods and tackle FSA differently. Specifically, given a fixed computational budget, we split it to (i) learn a task-specific feature extractor via PEFT and (ii) train a linear classifier on top. We call this scheme Two-Stage Few-Shot Adaptation (2SFS). Differently from established methods, our scheme enables a novel form of selective inference at a category level, i.e., at test time, only novel categories are embedded by the adapted text encoder, while embeddings of base categories are available within the classifier. Results with fixed hyperparameters across two settings, three backbones, and eleven datasets, show that 2SFS matches or surpasses the state-of-the-art, while established methods degrade significantly across settings.
@article{farina2025rethinking, title = {Rethinking Few-Shot Adaptation of Vision-Language Models in Two Stages}, author = {Farina, Matteo and Mancini, Massimiliano and Iacca, Giovanni and Ricci, Elisa}, journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2025}, } -
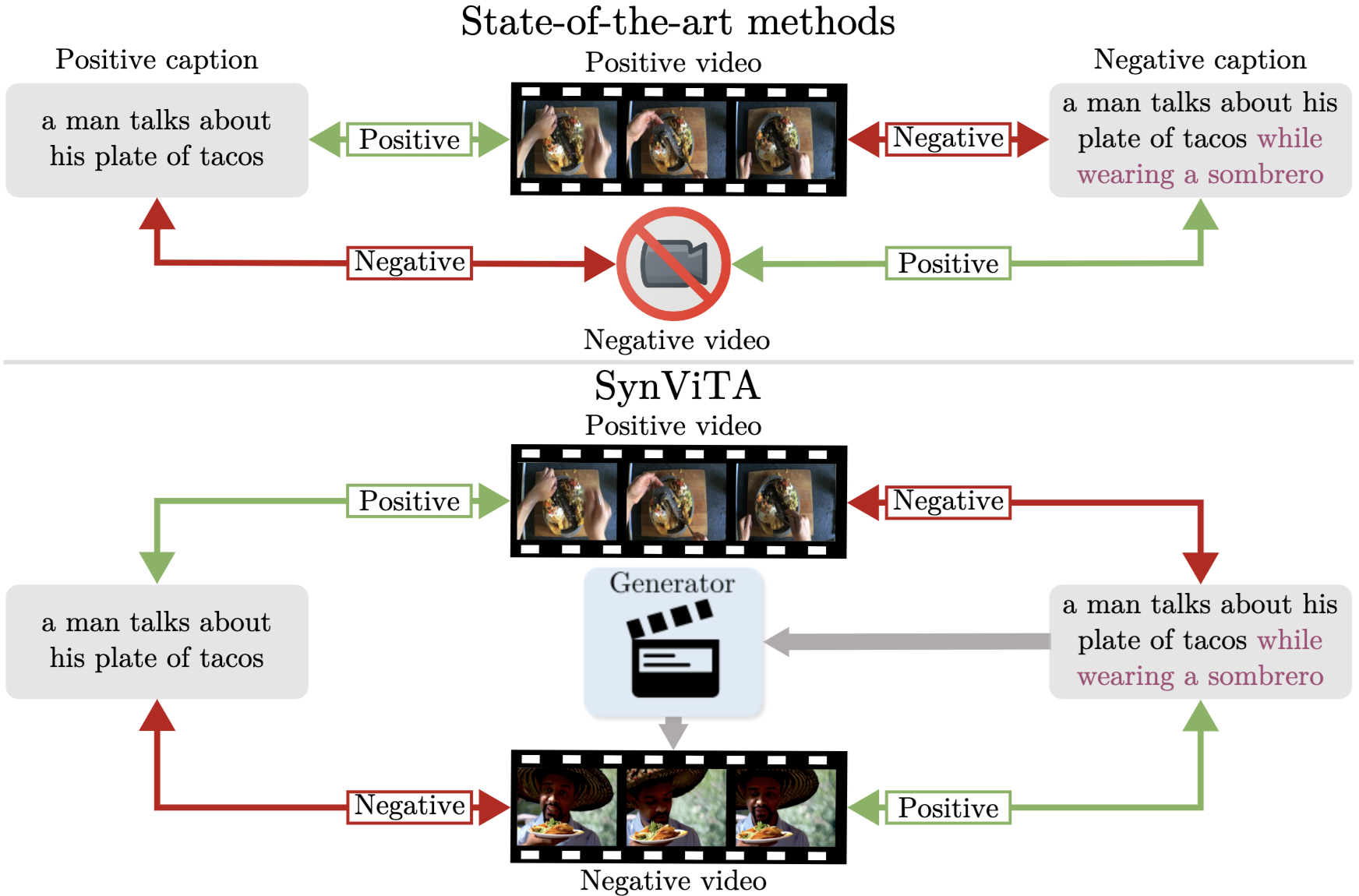 Can Text-to-Video Generation help Video-Language Alignment?Luca Zanella , Massimiliano Mancini, Willi Menapace , and 3 more authorsProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
Can Text-to-Video Generation help Video-Language Alignment?Luca Zanella , Massimiliano Mancini, Willi Menapace , and 3 more authorsProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025Recent video-language alignment models are trained on sets of videos, each with an associated positive caption and a negative caption generated by large language models. A problem with this procedure is that negative captions may introduce linguistic biases, i.e., concepts are seen only as negatives and never associated with a video. While a solution would be to collect videos for the negative captions, existing databases lack the fine-grained variations needed to cover all possible negatives. In this work, we study whether synthetic videos can help to overcome this issue. Our preliminary analysis with multiple generators shows that, while promising on some tasks, synthetic videos harm the performance of the model on others. We hypothesize this issue is linked to noise (semantic and visual) in the generated videos and develop a method, SynViTA, that accounts for those. SynViTA dynamically weights the contribution of each synthetic video based on how similar its target caption is w.r.t. the real counterpart. Moreover, a semantic consistency loss makes the model focus on fine-grained differences across captions, rather than differences in video appearance. Experiments show that, on average, SynViTA improves over existing methods on VideoCon test sets and SSv2-Temporal, SSv2-Events, and ATP-Hard benchmarks, being a first promising step for using synthetic videos when learning video-language models.
@article{zanella2025synvita, title = {Can Text-to-Video Generation help Video-Language Alignment?}, author = {Zanella, Luca and Mancini, Massimiliano and Menapace, Willi and Tulyakov, Sergey and Wang, Yiming and Ricci, Elisa}, journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2025}, } -
 Unlearning Personal Data from a Single ImageThomas De Min , Massimiliano Mancini, Stéphane Lathuilière , and 2 more authorsIn Transactions on Machine Learning Research , 2025
Unlearning Personal Data from a Single ImageThomas De Min , Massimiliano Mancini, Stéphane Lathuilière , and 2 more authorsIn Transactions on Machine Learning Research , 2025Machine unlearning aims to erase data from a model as if the latter never saw them during training. While existing approaches unlearn information from complete or partial access to the training data, this access can be limited over time due to privacy regulations. Currently, no setting or benchmark exists to probe the effectiveness of unlearning methods in such scenarios. To fill this gap, we propose a novel task we call One-Shot Unlearning of Personal Identities (1-SHUI) that evaluates unlearning models when the training data is not available. We focus on unlearning identity data, which is specifically relevant due to current regulations requiring personal data deletion after training. To cope with data absence, we expect users to provide a portraiting picture to aid unlearning. We design requests on CelebA, CelebA-HQ, and MUFAC with different unlearning set sizes to evaluate applicable methods in 1-SHUI. Moreover, we propose MetaUnlearn, an effective method that meta-learns to forget identities from a single image. Our findings indicate that existing approaches struggle when data availability is limited, especially when there is a dissimilarity between the provided samples and the training data.
@inproceedings{demin2025unlearning, title = {Unlearning Personal Data from a Single Image}, author = {De Min, Thomas and Mancini, Massimiliano and Lathuilière, Stéphane and Roy, Subhankar and Ricci, Elisa}, booktitle = {Transactions on Machine Learning Research}, year = {2025}, } -
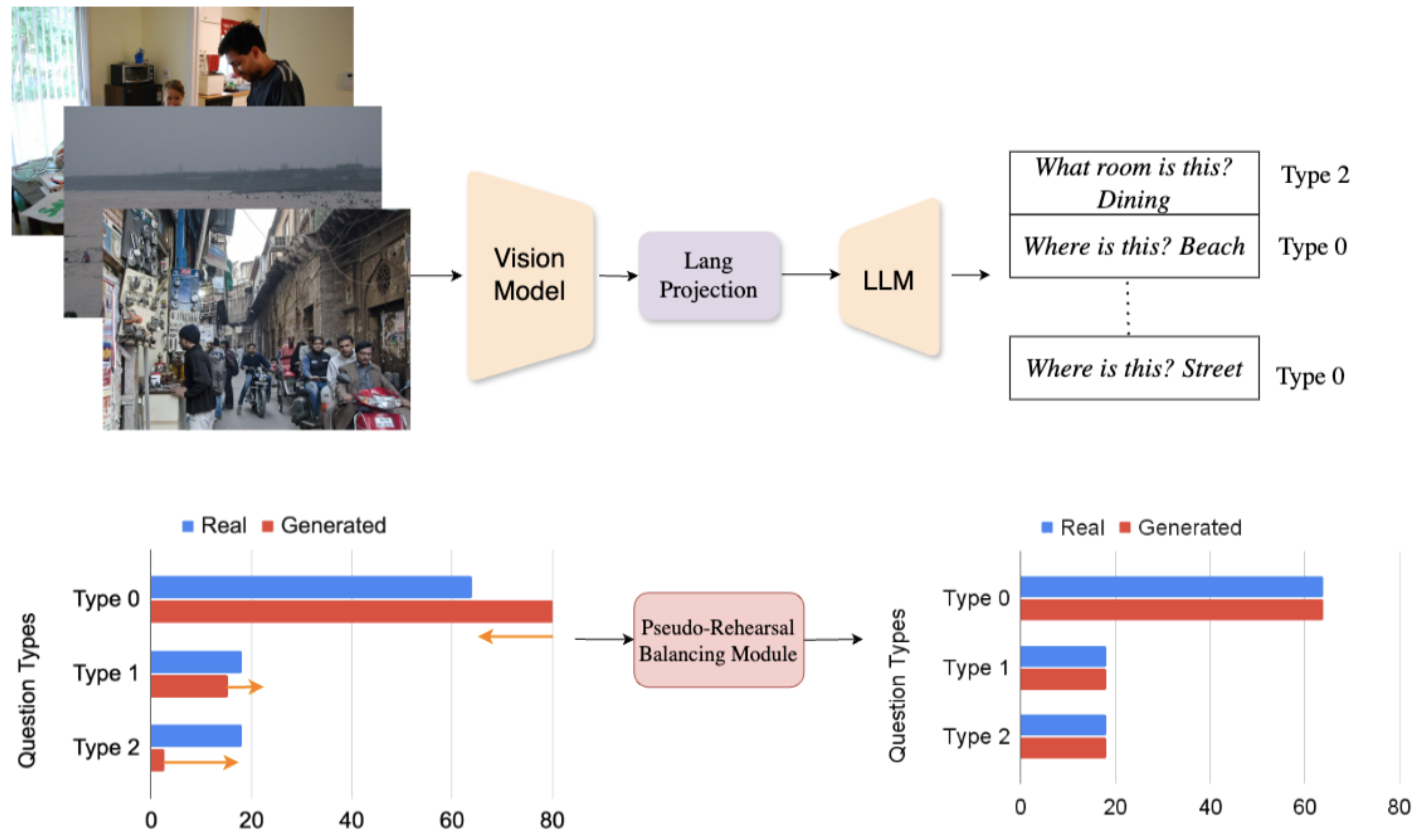 One VLM to Keep it Learning: Generation and Balancing for Data-free Continual Visual Question AnsweringDeepayan Das , Davide Talon , Massimiliano Mancini, and 2 more authorsIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , 2025
One VLM to Keep it Learning: Generation and Balancing for Data-free Continual Visual Question AnsweringDeepayan Das , Davide Talon , Massimiliano Mancini, and 2 more authorsIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , 2025Vision-Language Models (VLMs) have shown significant promise in Visual Question Answering (VQA) tasks by leveraging web-scale multimodal datasets. However, these models often struggle with continual learning due to catastrophic forgetting when adapting to new tasks. As an effective remedy to mitigate catastrophic forgetting, rehearsal strategy uses the data of past tasks upon learning new task. However, such strategy incurs the need of storing past data, which might not be feasible due to hardware constraints or privacy concerns. In this work, we propose the first data-free method that leverages the language generation capability of a VLM, instead of relying on external models, to produce pseudo-rehearsal data for addressing continual VQA. Our proposal, named as GaB, generates pseudo-rehearsal data by posing previous task questions on new task data. Yet, despite being effective, the distribution of generated questions skews towards the most frequently posed questions due to the limited and task-specific training data. To mitigate this issue, we introduce a pseudo-rehearsal balancing module that aligns the generated data towards the ground-truth data distribution using either the question meta-statistics or an unsupervised clustering method. We evaluate our proposed method on two recent benchmarks, i.e., VQACL-VQAv2 and CLOVE-function benchmarks. GaB outperforms all the data-free baselines with substantial improvement in maintaining VQA performance across evolving tasks, while being on-par with methods with access to the past data.
@inproceedings{das2025onevlm, title = {One VLM to Keep it Learning: Generation and Balancing for Data-free Continual Visual Question Answering}, author = {Das, Deepayan and Talon, Davide and Mancini, Massimiliano and Wang, Yiming and Ricci, Elisa}, booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, } -
 3D Part Segmentation via Geometric Aggregation of 2D Visual FeaturesMarco Garosi , Riccardo Tedoldi , Davide Boscaini , and 3 more authorsIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , 2025
3D Part Segmentation via Geometric Aggregation of 2D Visual FeaturesMarco Garosi , Riccardo Tedoldi , Davide Boscaini , and 3 more authorsIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , 2025Supervised 3D part segmentation models are tailored for a fixed set of objects and parts, limiting their transferability to open-set, real-world scenarios. Recent works have explored vision-language models (VLMs) as a promising alternative, using multi-view rendering and textual prompting to identify object parts. However, naively applying VLMs in this context introduces several drawbacks, such as the need for meticulous prompt engineering, and fails to leverage the 3D geometric structure of objects. To address these limitations, we propose COPS, a COmprehensive model for Parts Segmentation that blends the semantics extracted from visual concepts and 3D geometry to effectively identify object parts. COPS renders a point cloud from multiple viewpoints, extracts 2D features, projects them back to 3D, and uses a novel geometric-aware feature aggregation procedure to ensure spatial and semantic consistency. Finally, it clusters points into parts and labels them. We demonstrate that COPS is efficient, scalable, and achieves zero-shot state-of-the-art performance across five datasets, covering synthetic and real-world data, texture-less and coloured objects, as well as rigid and non-rigid shapes.
@inproceedings{garosi20253d, title = {3D Part Segmentation via Geometric Aggregation of 2D Visual Features}, author = {Garosi, Marco and Tedoldi, Riccardo and Boscaini, Davide and Mancini, Massimiliano and Sebe, Nicu and Poiesi, Fabio}, booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, }









2024
-
 Frustratingly Easy Test-Time Adaptation of Vision-Language ModelsMatteo Farina , Gianni Franchi , Giovanni Iacca , and 2 more authorsAdvances in Neural Information Processing Systems (NeurIPS), Dec 2024
Frustratingly Easy Test-Time Adaptation of Vision-Language ModelsMatteo Farina , Gianni Franchi , Giovanni Iacca , and 2 more authorsAdvances in Neural Information Processing Systems (NeurIPS), Dec 2024Vision-Language Models seamlessly discriminate among arbitrary semantic categories, yet they still suffer from poor generalization when presented with challenging examples. For this reason, Episodic Test-Time Adaptation (TTA) strategies have recently emerged as powerful techniques to adapt VLMs in the presence of a single unlabeled image. The recent literature on TTA is dominated by the paradigm of prompt tuning by Marginal Entropy Minimization, which, relying on online backpropagation, inevitably slows down inference while increasing memory. In this work, we theoretically investigate the properties of this approach and unveil that a surprisingly strong TTA method lies dormant and hidden within it. We term this approach ZERO (TTA with “zero” temperature), whose design is both incredibly effective and frustratingly simple: augment N times, predict, retain the most confident predictions, and marginalize after setting the Softmax temperature to zero. Remarkably, ZERO requires a single batched forward pass through the vision encoder only and no backward passes. We thoroughly evaluate our approach following the experimental protocol established in the literature and show that ZERO largely surpasses or compares favorably w.r.t. the state-of-the-art while being almost 10× faster and 13× more memory friendly than standard Test-Time Prompt Tuning. Thanks to its simplicity and comparatively negligible computation, ZERO can serve as a strong baseline for future work in this field. Code will be available.
@article{farina2024frustratingly, title = {Frustratingly Easy Test-Time Adaptation of Vision-Language Models}, author = {Farina, Matteo and Franchi, Gianni and Iacca, Giovanni and Mancini, Massimiliano and Ricci, Elisa}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2024}, month = dec, } -
 The Phantom Menace: Unmasking Privacy Leakages in Vision-Language ModelsSimone Caldarella , Massimiliano Mancini, Elisa Ricci , and 1 more authorIn European Conference on Computer Vision (ECCV) Workshops , Oct 2024
The Phantom Menace: Unmasking Privacy Leakages in Vision-Language ModelsSimone Caldarella , Massimiliano Mancini, Elisa Ricci , and 1 more authorIn European Conference on Computer Vision (ECCV) Workshops , Oct 2024Vision-Language Models (VLMs) combine visual and textual understanding, rendering them well-suited for diverse tasks like generating image captions and answering visual questions across various domains. However, these capabilities are built upon training on large amount of uncurated data crawled from the web. The latter may include sensitive information that VLMs could memorize and leak, raising significant privacy concerns. In this paper, we assess whether these vulnerabilities exist, focusing on identity leakage. Our study leads to three key findings: (i) VLMs leak identity information, even when the vision-language alignment and the fine-tuning use anonymized data; (ii) context has little influence on identity leakage; (iii) simple, widely used anonymization techniques, like blurring, are not sufficient to address the problem. These findings underscore the urgent need for robust privacy protection strategies when deploying VLMs. Ethical awareness and responsible development practices are essential to mitigate these risks.
@inproceedings{caldarella2024phantom, title = {The Phantom Menace: Unmasking Privacy Leakages in Vision-Language Models}, author = {Caldarella, Simone and Mancini, Massimiliano and Ricci, Elisa and Aljundi, Rahaf}, booktitle = {European Conference on Computer Vision (ECCV) Workshops}, year = {2024}, month = oct, } -
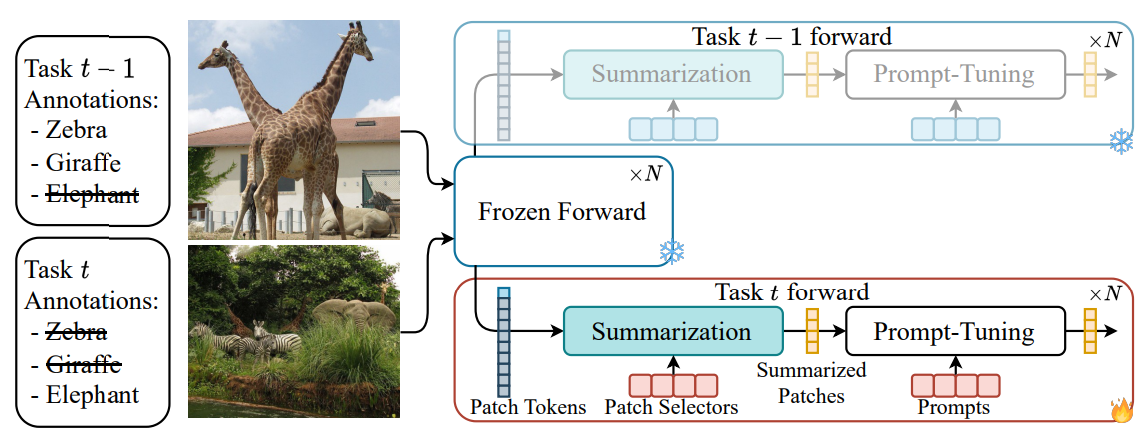 Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental LearningThomas De Min , Massimiliano Mancini, Stéphane Lathuilière , and 2 more authorsIn Conference on Lifelong Learning Agents , Oct 2024
Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental LearningThomas De Min , Massimiliano Mancini, Stéphane Lathuilière , and 2 more authorsIn Conference on Lifelong Learning Agents , Oct 2024Prompt tuning has emerged as an effective rehearsal-free technique for class-incremental learning (CIL) that learns a tiny set of task-specific parameters (or prompts) to instruct a pre-trained transformer to learn on a sequence of tasks. Albeit effective, prompt tuning methods do not lend well in the multi-label class incremental learning (MLCIL) scenario (where an image contains multiple foreground classes) due to the ambiguity in selecting the correct prompt(s) corresponding to different foreground objects belonging to multiple tasks. To circumvent this issue we propose to eliminate the prompt selection mechanism by maintaining task-specific pathways, which allow us to learn representations that do not interact with the ones from the other tasks. Since independent pathways in truly incremental scenarios will result in an explosion of computation due to the quadratically complex multi-head self-attention (MSA) operation in prompt tuning, we propose to reduce the original patch token embeddings into summarized tokens. Prompt tuning is then applied to these fewer summarized tokens to compute the final representation. Our proposed method Multi-Label class incremental learning via summarising pAtch tokeN Embeddings (MULTI-LANE) enables learning disentangled task-specific representations in MLCIL while ensuring fast inference. We conduct experiments in common benchmarks and demonstrate that our MULTI-LANE achieves a new state-of-the-art in MLCIL. Additionally, we show that MULTI-LANE is also competitive in the CIL setting.
@inproceedings{demin2024multilane, title = {Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning}, author = {De Min, Thomas and Mancini, Massimiliano and Lathuilière, Stéphane and Roy, Subhankar and Ricci, Elisa}, booktitle = {Conference on Lifelong Learning Agents}, year = {2024}, } -
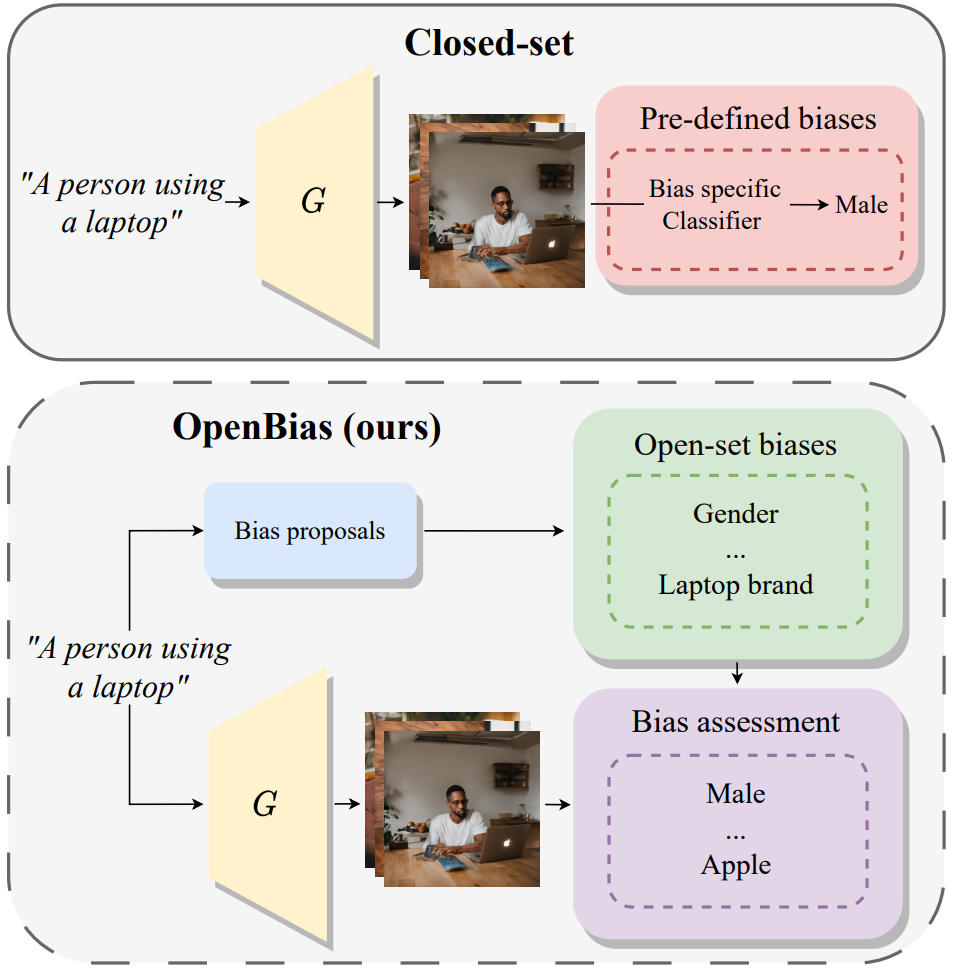 OpenBias: Open-set Bias Detection in Text-to-Image Generative ModelsMoreno D’Incà , Elia Peruzzo , Massimiliano Mancini, and 6 more authorsIEEE/CVF Conference on Computer Vision and Pattern Recognition, Oct 2024
OpenBias: Open-set Bias Detection in Text-to-Image Generative ModelsMoreno D’Incà , Elia Peruzzo , Massimiliano Mancini, and 6 more authorsIEEE/CVF Conference on Computer Vision and Pattern Recognition, Oct 2024Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However existing works focus on detecting closed sets of biases defined a priori limiting the studies to well-known concepts. In this paper we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias a new pipeline that identifies and quantifies the severity of biases agnostically without access to any precompiled set. OpenBias has three stages. In the first phase we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly the target generative model produces images using the same set of captions. Lastly a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5 2 and XL emphasizing new biases never investigated before. Via quantitative experiments we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
@article{dinca2024openbias, title = {OpenBias: Open-set Bias Detection in Text-to-Image Generative Models}, author = {D'Incà, Moreno and Peruzzo, Elia and Mancini, Massimiliano and Xu, Dejia and Goel, Vidit and Xu, Xingqian and Wang, Zhangyang and Shi, Humphrey and Sebe, Nicu}, journal = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2024}, } -
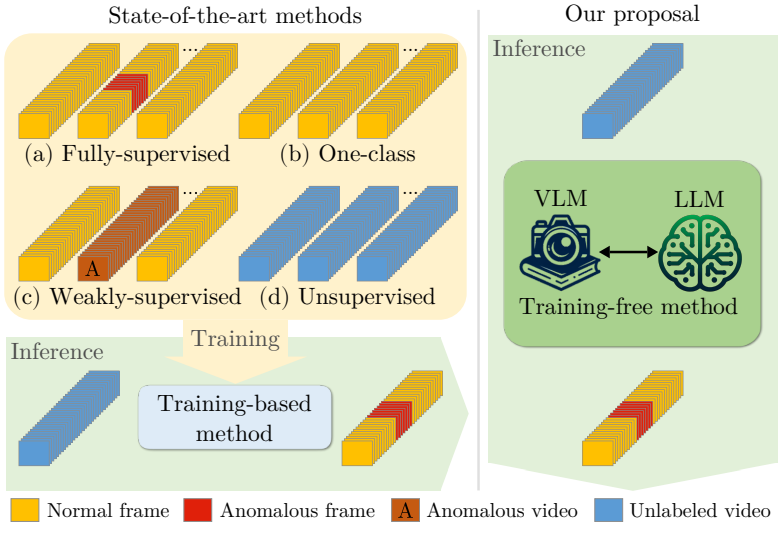 Harnessing Large Language Models for Training-free Video Anomaly DetectionLuca Zanella , Willi Menapace , Massimiliano Mancini, and 2 more authorsIEEE/CVF Conference on Computer Vision and Pattern Recognition, Oct 2024
Harnessing Large Language Models for Training-free Video Anomaly DetectionLuca Zanella , Willi Menapace , Massimiliano Mancini, and 2 more authorsIEEE/CVF Conference on Computer Vision and Pattern Recognition, Oct 2024Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision one-class supervision or in an unsupervised setting. Training-based methods are prone to be domain-specific thus being costly for practical deployment as any domain change will involve data collection and model training. In this paper we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD) a method tackling VAD in a novel training-free paradigm exploiting the capabilities of pre-trained large language models (LLMs) and existing vision-language models (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effective techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real-world surveillance scenarios (UCF-Crime and XD-Violence) showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
@article{zanella2024lavad, title = {Harnessing Large Language Models for Training-free Video Anomaly Detection}, author = {Zanella, Luca and Menapace, Willi and Mancini, Massimiliano and Wang, Yiming and Ricci, Elisa}, journal = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2024}, } -
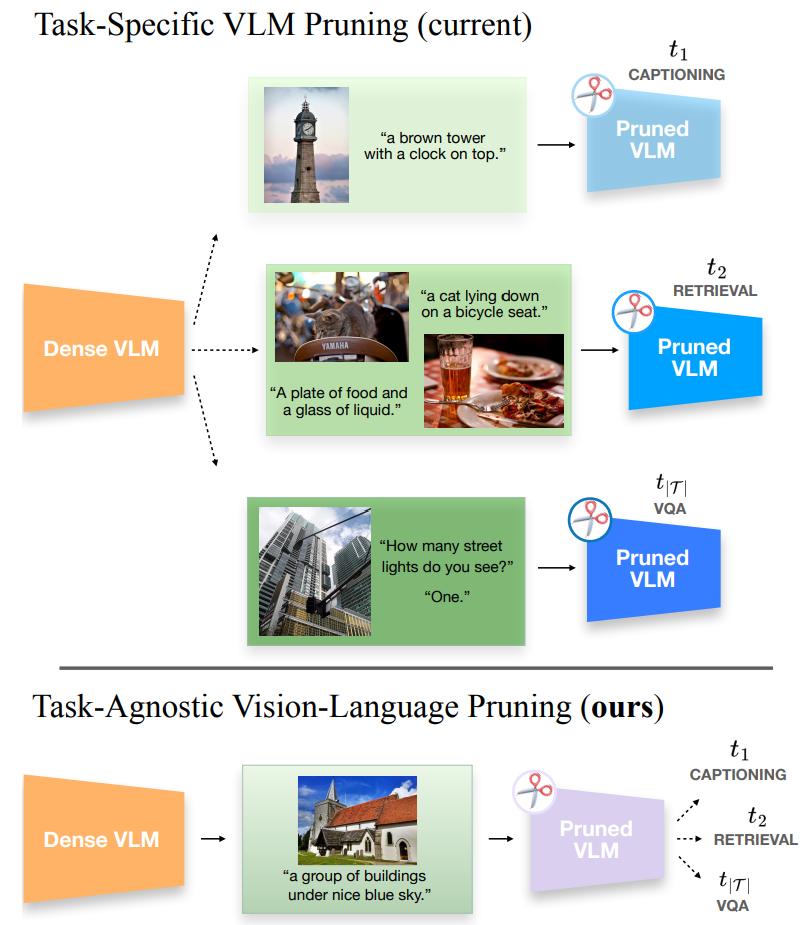 MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language PruningMatteo Farina , Massimiliano Mancini, Elia Cunegatti , and 3 more authorsIEEE/CVF Conference on Computer Vision and Pattern Recognition, Oct 2024
MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language PruningMatteo Farina , Massimiliano Mancini, Elia Cunegatti , and 3 more authorsIEEE/CVF Conference on Computer Vision and Pattern Recognition, Oct 2024While excellent in transfer learning Vision-Language models (VLMs) come with high computational costs due to their large number of parameters. To address this issue removing parameters via model pruning is a viable solution. However existing techniques for VLMs are task-specific and thus require pruning the network from scratch for each new task of interest. In this work we explore a new direction: Task-Agnostic Vision-Language Pruning (TA-VLP). Given a pretrained VLM the goal is to find a unique pruned counterpart transferable to multiple unknown downstream tasks. In this challenging setting the transferable representations already encoded in the pretrained model are a key aspect to preserve. Thus we propose Multimodal Flow Pruning (MULTIFLOW) a first gradient-free pruning framework for TA-VLP where: (i) the importance of a parameter is expressed in terms of its magnitude and its information flow by incorporating the saliency of the neurons it connects; and (ii) pruning is driven by the emergent (multimodal) distribution of the VLM parameters after pretraining. We benchmark eight state-of-the-art pruning algorithms in the context of TA-VLP experimenting with two VLMs three vision-language tasks and three pruning ratios. Our experimental results show that MULTIFLOW outperforms recent sophisticated combinatorial competitors in the vast majority of the cases paving the way towards addressing TA-VLP. The code is publicly available at https://github.com/FarinaMatteo/multiflow.
@article{farina2024multiflow, title = {MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning}, author = {Farina, Matteo and Mancini, Massimiliano and Cunegatti, Elia and Liu, Gaowen and Iacca, Giovanni and Ricci, Elisa}, journal = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2024}, } -
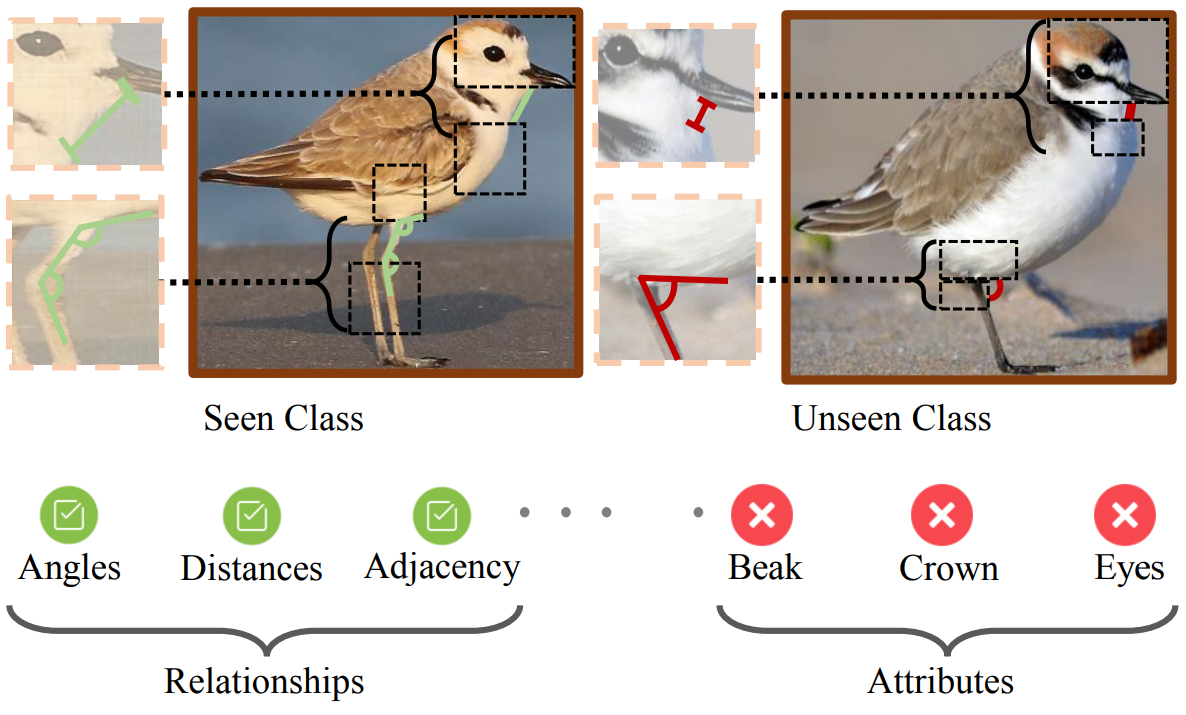 Relational Proxies: Fine-Grained Relationships as Zero-Shot DiscriminatorsAbhra Chaudhuri , Massimiliano Mancini, Zeynep Akata , and 1 more authorIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2024
Relational Proxies: Fine-Grained Relationships as Zero-Shot DiscriminatorsAbhra Chaudhuri , Massimiliano Mancini, Zeynep Akata , and 1 more authorIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2024Visual categories that largely share the same set of local parts cannot be discriminated based on part information alone, as they mostly differ in the way the local parts relate to the overall global structure of the object. We propose Relational Proxies , a novel approach that leverages the relational information between the global and local views of an object for encoding its semantic label, even for categories it has not encountered during training. Starting with a rigorous formalization of the notion of distinguishability between categories that share attributes, we prove the necessary and sufficient conditions that a model must satisfy in order to learn the underlying decision boundaries to tell them apart. We design Relational Proxies based on our theoretical findings and evaluate it on seven challenging fine-grained benchmark datasets and achieve state-of-the-art results on all of them, surpassing the performance of all existing works with a margin exceeding 4% in some cases. We additionally show that Relational Proxies also generalizes to the zero-shot setting, where it can efficiently leverage emergent relationships among attributes and image views to generalize to unseen categories, surpassing current state-of-the-art in both the non-generative and generative settings.
@article{chaudhuri2024relational, title = {Relational Proxies: Fine-Grained Relationships as Zero-Shot Discriminators}, author = {Chaudhuri, Abhra and Mancini, Massimiliano and Akata, Zeynep and Dutta, Anjan}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, year = {2024}, volume = {46}, number = {12}, pages = {8653-8664}, doi = {10.1109/TPAMI.2024.3408913}, } -
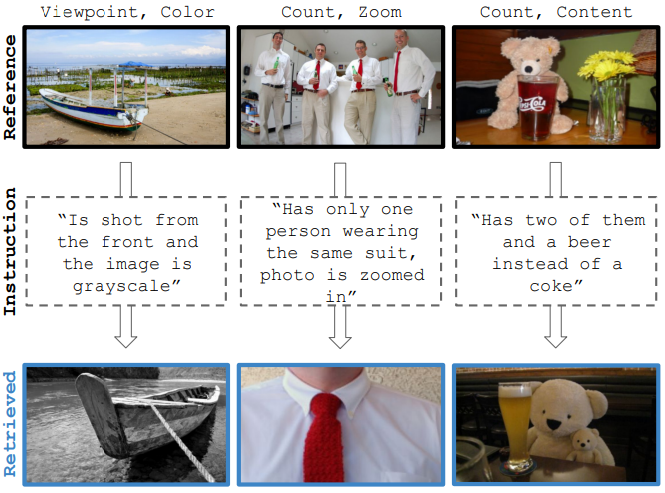 Vision-by-Language for Training-Free Compositional Image RetrievalShyamgopal Karthik , Karsten Roth , Massimiliano Mancini, and 1 more authorIn International Conference on Learning Representations (ICLR) , Oct 2024
Vision-by-Language for Training-Free Compositional Image RetrievalShyamgopal Karthik , Karsten Roth , Massimiliano Mancini, and 1 more authorIn International Conference on Learning Representations (ICLR) , Oct 2024Given an image and a target modification (e.g an image of the Eiffel tower and the text “without people and at night-time”), Compositional Image Retrieval (CIR) aims to retrieve the relevant target image in a database. While supervised approaches rely on annotating triplets that is costly (i.e. query image, textual modification, and target image), recent research sidesteps this need by using large-scale vision-language models (VLMs), performing Zero-Shot CIR (ZS-CIR). However, state-of-the-art approaches in ZS-CIR still require training task-specific, customized models over large amounts of image-text pairs. In this work, we proposeto tackle CIR in a training-free manner via our Compositional Image Retrieval through Vision-by-Language (CIReVL), a simple, yet human-understandable and scalable pipeline that effectively recombines large-scale VLMs with large language models (LLMs). By captioning the reference image using a pre-trained generative VLM and asking a LLM to recompose the caption based on the textual target modification for subsequent retrieval via e.g. CLIP, we achieve modular language reasoning. In four ZS-CIR benchmarks, we find competitive, in-part state-of-the-art performance - improving over supervised methods Moreover, the modularity of CIReVL offers simple scalability without re-training, allowing us to both investigate scaling laws and bottlenecks for ZS-CIR while easily scaling up to in parts more than double of previously reported results. Finally, we show that CIReVL makes CIR human-understandable by composing image and text in a modular fashion in the language domain, thereby making it intervenable, allowing to post-hoc re-align failure cases. Code will be released upon acceptance.
@inproceedings{Karthik_2024_ICLR, author = {Karthik, Shyamgopal and Roth, Karsten and Mancini, Massimiliano and Akata, Zeynep}, title = {Vision-by-Language for Training-Free Compositional Image Retrieval}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2024}, } -
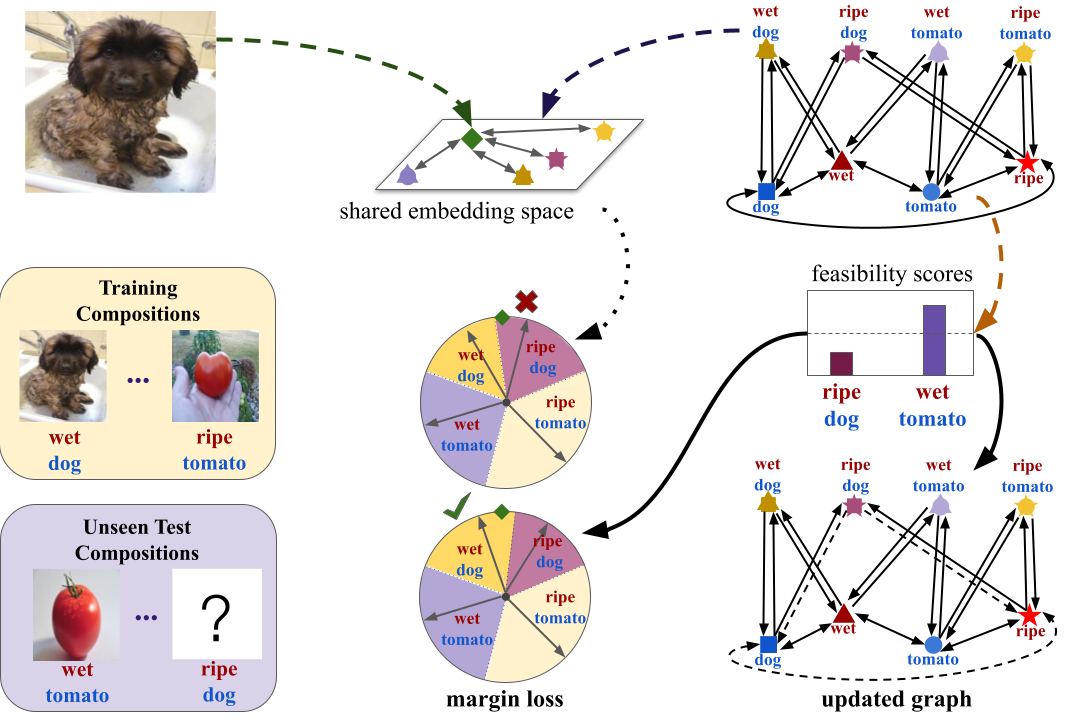 Learning Graph Embeddings for Open World Compositional Zero-Shot LearningMassimiliano Mancini, Muhammad Ferjad Naeem , Yongqin Xian , and 1 more authorIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2024
Learning Graph Embeddings for Open World Compositional Zero-Shot LearningMassimiliano Mancini, Muhammad Ferjad Naeem , Yongqin Xian , and 1 more authorIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2024Compositional Zero-Shot learning (CZSL) aims to recognize unseen compositions of state and object visual primitives seen during training. A problem with standard CZSL is the assumption of knowing which unseen compositions will be available at test time. In this work, we overcome this assumption operating on the open world setting, where no limit is imposed on the compositional space at test time, and the search space contains a large number of unseen compositions. To address this problem, we propose a new approach, Compositional Cosine Graph Embeddings (Co-CGE), based on two principles. First, Co-CGE models the dependency between states, objects and their compositions through a graph convolutional neural network. The graph propagates information from seen to unseen concepts, improving their representations. Second, since not all unseen compositions are equally feasible, and less feasible ones may damage the learned representations, Co-CGE estimates a feasibility score for each unseen composition, using the scores as margins in a cosine similarity-based loss and as weights in the adjacency matrix of the graphs. Experiments show that our approach achieves state-of-the-art performances in standard CZSL while outperforming previous methods in the open world scenario.
@article{9745371, author = {Mancini, Massimiliano and Naeem, Muhammad Ferjad and Xian, Yongqin and Akata, Zeynep}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, title = {Learning Graph Embeddings for Open World Compositional Zero-Shot Learning}, year = {2024}, volume = {46}, number = {3}, pages = {1545-1560}, doi = {10.1109/TPAMI.2022.3163667}, } -
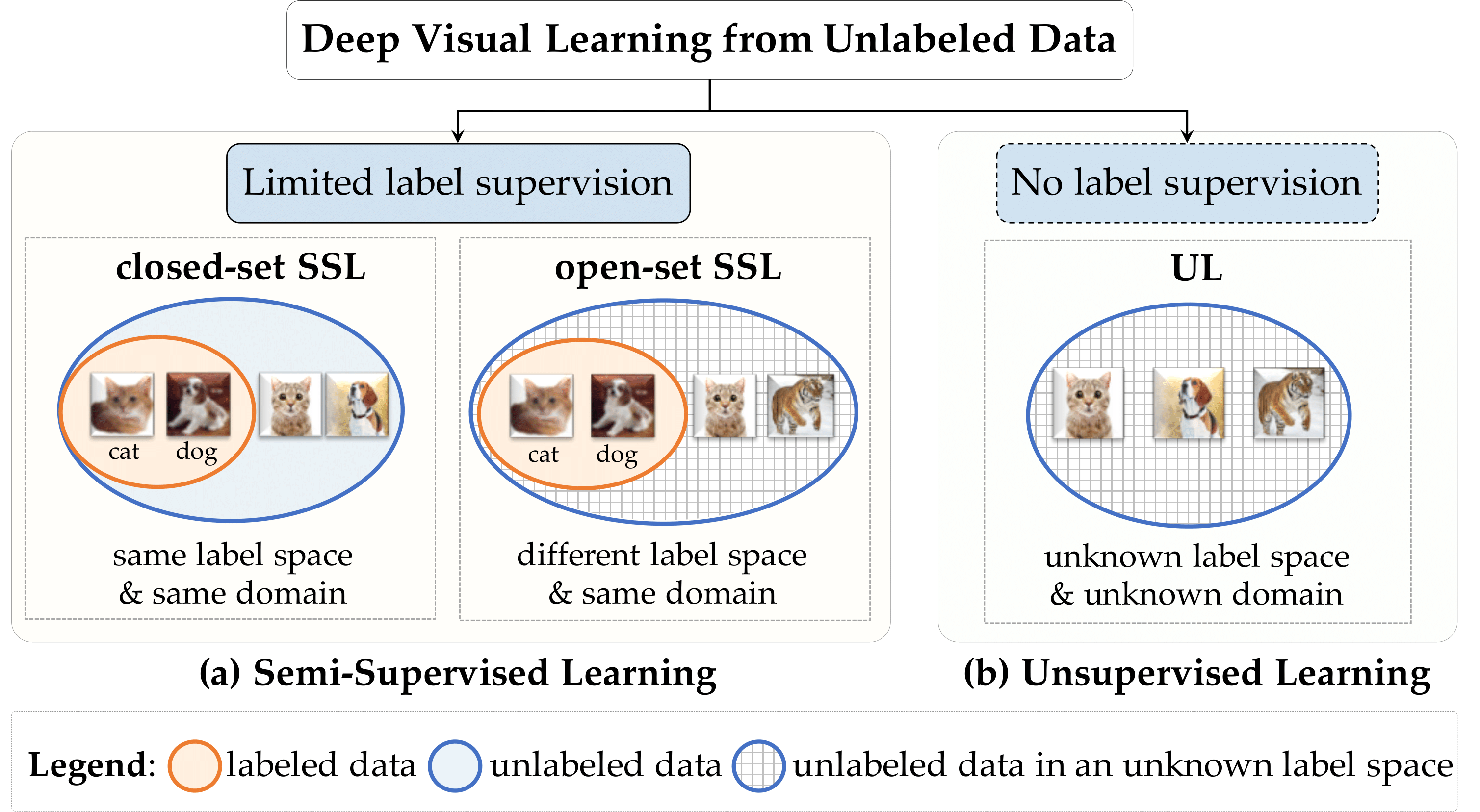 Semi-Supervised and Unsupervised Deep Visual Learning: A SurveyYanbei Chen , Massimiliano Mancini, Xiatian Zhu , and 1 more authorIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2024
Semi-Supervised and Unsupervised Deep Visual Learning: A SurveyYanbei Chen , Massimiliano Mancini, Xiatian Zhu , and 1 more authorIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2024State-of-the-art deep learning models are often trained with a large amount of costly labeled training data. However, requiring exhaustive manual annotations may degrade the model’s generalizability in the limited-label regime.Semi-supervised learning and unsupervised learning offer promising paradigms to learn from an abundance of unlabeled visual data. Recent progress in these paradigms has indicated the strong benefits of leveraging unlabeled data to improve model generalization and provide better model initialization. In this survey, we review the recent advanced deep learning algorithms on semi-supervised learning (SSL) and unsupervised learning (UL) for visual recognition from a unified perspective. To offer a holistic understanding of the state-of-the-art in these areas, we propose a unified taxonomy. We categorize existing representative SSL and UL with comprehensive and insightful analysis to highlight their design rationales in different learning scenarios and applications in different computer vision tasks. Lastly, we discuss the emerging trends and open challenges in SSL and UL to shed light on future critical research directions.
@article{chen2022semi, title = {Semi-Supervised and Unsupervised Deep Visual Learning: A Survey}, author = {Chen, Yanbei and Mancini, Massimiliano and Zhu, Xiatian and Akata, Zeynep}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, year = {2024}, volume = {46}, number = {3}, pages = {61327-1347}, publisher = {IEEE}, }










2023
-
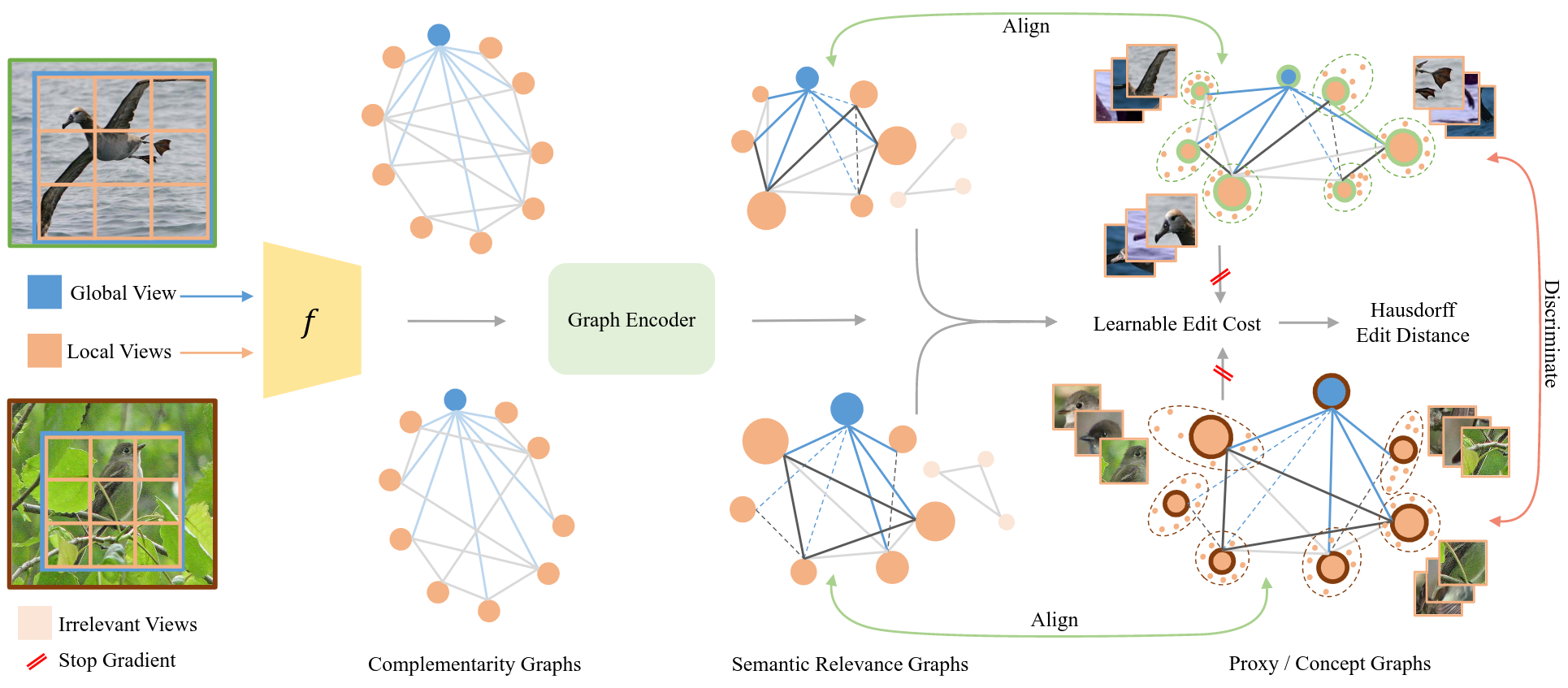 Transitivity Recovering Decompositions: Interpretable and Robust Fine-Grained RelationshipsAbhra Chaudhuri , Massimiliano Mancini, Zeynep Akata , and 1 more authorIn Thirty-seventh Conference on Neural Information Processing Systems , Oct 2023
Transitivity Recovering Decompositions: Interpretable and Robust Fine-Grained RelationshipsAbhra Chaudhuri , Massimiliano Mancini, Zeynep Akata , and 1 more authorIn Thirty-seventh Conference on Neural Information Processing Systems , Oct 2023Recent advances in fine-grained representation learning leverage local-to-global (emergent) relationships for achieving state-of-the-art results. The relational representations relied upon by such methods, however, are abstract. We aim to deconstruct this abstraction by expressing them as interpretable graphs over image views. We begin by theoretically showing that abstract relational representations are nothing but a way of recovering transitive relationships among local views. Based on this, we design Transitivity Recovering Decompositions (TRD), a graph-space search algorithm that identifies interpretable equivalents of abstract emergent relationships at both instance and class levels, and with no post-hoc computations. We additionally show that TRD is provably robust to noisy views, with empirical evidence also supporting this finding. The latter allows TRD to perform at par or even better than the state-of-the-art, while being fully interpretable.
@inproceedings{chaudhuri2023transitivity, title = {Transitivity Recovering Decompositions: Interpretable and Robust Fine-Grained Relationships}, author = {Chaudhuri, Abhra and Mancini, Massimiliano and Akata, Zeynep and Dutta, Anjan}, booktitle = {Thirty-seventh Conference on Neural Information Processing Systems}, year = {2023}, } -
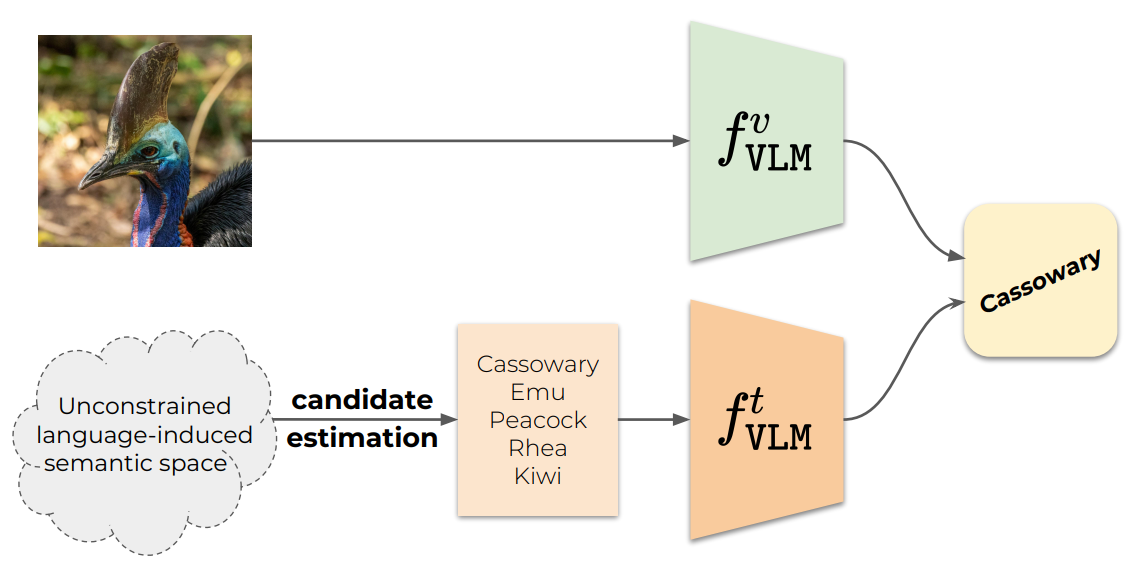 Vocabulary-free Image ClassificationAlessandro Conti , Enrico Fini , Massimiliano Mancini, and 3 more authorsAdvances in Neural Information Processing Systems (NeurIPS), Oct 2023
Vocabulary-free Image ClassificationAlessandro Conti , Enrico Fini , Massimiliano Mancini, and 3 more authorsAdvances in Neural Information Processing Systems (NeurIPS), Oct 2023Recent advances in large vision-language models have revolutionized the image classification paradigm. Despite showing impressive zero-shot capabilities, a pre-defined set of categories, a.k.a. the vocabulary, is assumed at test time for composing the textual prompts. However, such assumption can be impractical when the semantic context is unknown and evolving. We thus formalize a novel task, termed as Vocabulary-free Image Classification (VIC), where we aim to assign to an input image a class that resides in an unconstrained language-induced semantic space, without the prerequisite of a known vocabulary. VIC is a challenging task as the semantic space is extremely large, containing millions of concepts, with hard-to-discriminate fine-grained categories.
@article{conti2023vocabulary, title = {Vocabulary-free Image Classification}, author = {Conti, Alessandro and Fini, Enrico and Mancini, Massimiliano and Rota, Paolo and Wang, Yiming and Ricci, Elisa}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2023}, } -
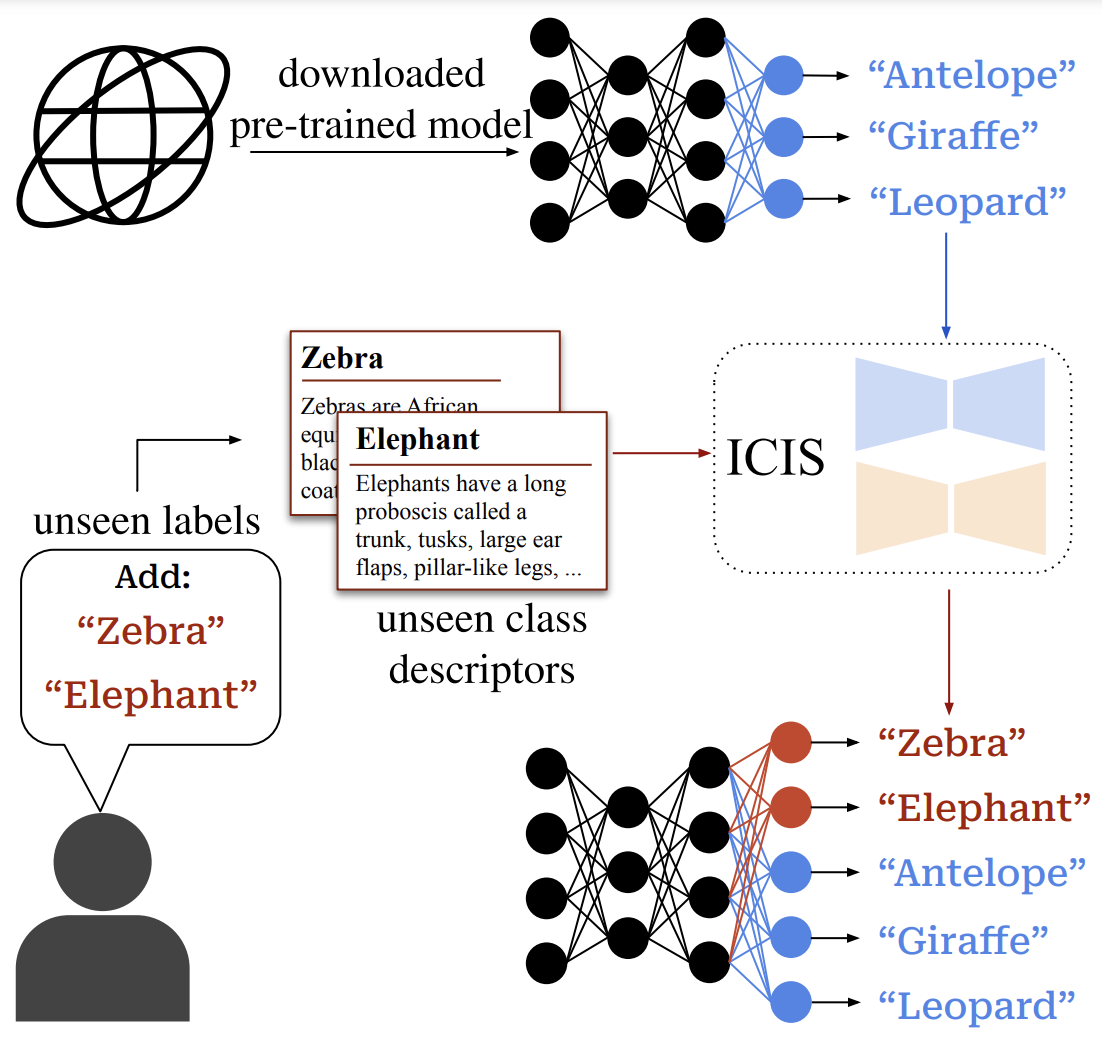 Image-free Classifier Injection for Zero-Shot ClassificationAnders Christensen , Massimiliano Mancini, A. Sophia Koepke , and 2 more authorsIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023
Image-free Classifier Injection for Zero-Shot ClassificationAnders Christensen , Massimiliano Mancini, A. Sophia Koepke , and 2 more authorsIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023Zero-shot learning models achieve remarkable results on image classification for samples from classes that were not seen during training. However, such models must be trained from scratch with specialised methods: therefore, access to a training dataset is required when the need for zero-shot classification arises. In this paper, we aim to equip pre-trained models with zero-shot classification capabilities without the use of image data. We achieve this with our proposed Image-free Classifier Injection with Semantics (ICIS) that injects classifiers for new, unseen classes into pre-trained classification models in a post-hoc fashion without relying on image data. Instead, the existing classifier weights and simple class-wise descriptors, such as class names or attributes, are used. ICIS has two encoder-decoder networks that learn to reconstruct classifier weights from descriptors (and vice versa), exploiting (cross-)reconstruction and cosine losses to regularise the decoding process. Notably, ICIS can be cheaply trained and applied directly on top of pre-trained classification models. Experiments on benchmark ZSL datasets show that ICIS produces unseen classifier weights that achieve strong (generalised) zero-shot classification performance.
@inproceedings{christensen2023image, title = {Image-free Classifier Injection for Zero-Shot Classification}, author = {Christensen, Anders and Mancini, Massimiliano and Koepke, A. Sophia and Winther, Ole and Akata, Zeynep}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV) 2023}, year = {2023}, } -
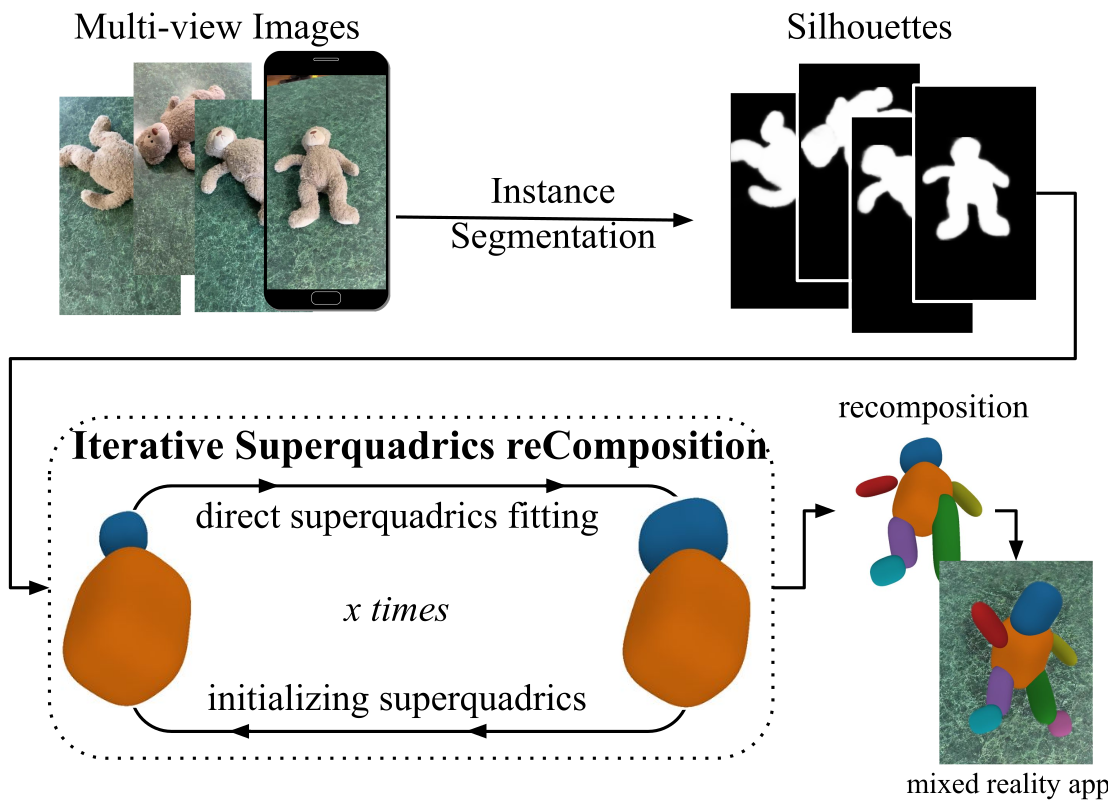 Iterative Superquadric Recomposition of 3D Objects from Multiple ViewsStephan Alaniz , Massimiliano Mancini, and Zeynep AkataIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023
Iterative Superquadric Recomposition of 3D Objects from Multiple ViewsStephan Alaniz , Massimiliano Mancini, and Zeynep AkataIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023Humans are good at recomposing novel objects, i.e they can identify commonalities between unknown objects from general structure to finer detail, an ability difficult to replicate by machines. We propose a framework, ISCO, to recompose an object using 3D superquadrics as semantic parts directly from 2D views without training a model that uses 3D supervision. To achieve this, we optimize the superquadric parameters that compose a specific instance of the object, comparing its rendered 3D view and 2D image silhouette. Our ISCO framework iteratively adds new superquadrics wherever the reconstruction error is high, abstracting first coarse regions and then finer details of the target object. With this simple coarse-to-fine inductive bias, ISCO provides consistent superquadrics for related object parts, despite not having any semantic supervision. Since ISCO does not train any neural network, it is also inherently robust to out of distribution objects. Experiments show that, compared to recent single instance superquadrics reconstruction approaches, ISCO provides consistently more accurate 3D reconstructions, even from images in the wild.
@inproceedings{alaniz2023iterative, title = {Iterative Superquadric Recomposition of 3D Objects from Multiple Views}, author = {Alaniz, Stephan and Mancini, Massimiliano and Akata, Zeynep}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV) 2023}, year = {2023}, } -
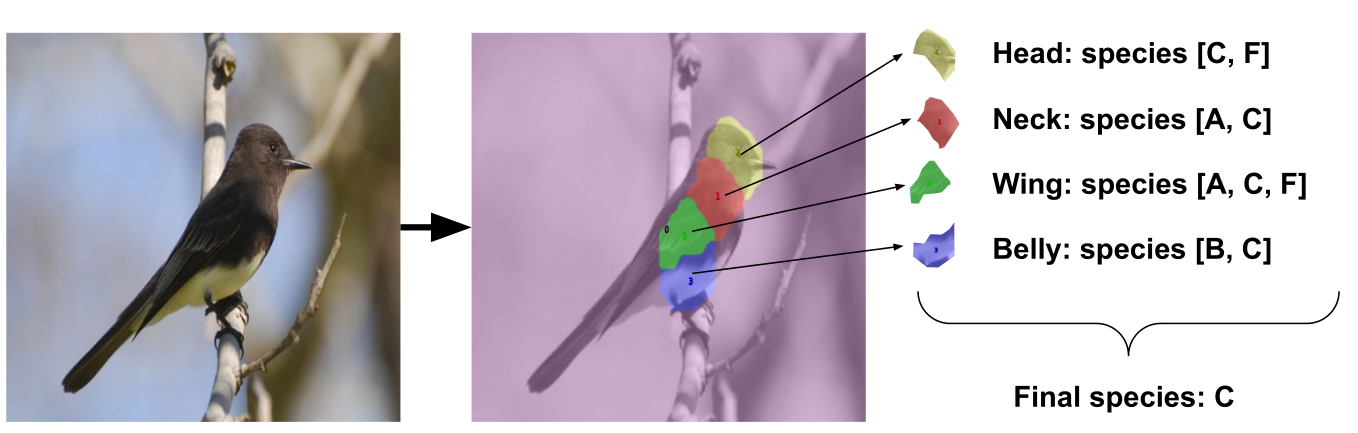 PDiscoNet: Semantically consistent part discovery for fine-grained recognitionRobert Klis , Stephan Alaniz , Massimiliano Mancini, and 4 more authorsIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023
PDiscoNet: Semantically consistent part discovery for fine-grained recognitionRobert Klis , Stephan Alaniz , Massimiliano Mancini, and 4 more authorsIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023Fine-grained classification often requires recognizing specific object parts, such as beak shape and wing patterns for birds. Encouraging a fine-grained classification model to first detect such parts and then using them to infer the class could help us gauge whether the model is indeed looking at the right details better than with interpretability methods that provide a single attribution map. We propose PDiscoNet to discover object parts by using only image-level class labels along with priors encouraging the parts to be: discriminative, compact, distinct from each other, equivariant to rigid transforms, and active in at least some of the images. In addition to using the appropriate losses to encode these priors, we propose to use part-dropout, where full part feature vectors are dropped at once to prevent a single part from dominating in the classification, and part feature vector modulation, which makes the information coming from each part distinct from the perspective of the classifier. Our results on CUB, CelebA, and PartImageNet show that the proposed method provides substantially better part discovery performance than previous methods while not requiring any additional hyper-parameter tuning and without penalizing the classification performance.
@inproceedings{vanderklis2023pdisconet, title = {PDiscoNet: Semantically consistent part discovery for fine-grained recognition}, author = {van der Klis, Robert and Alaniz, Stephan and Mancini, Massimiliano and Dantas, Cassio F. and Ienco, Dino and Akata, Zeynep and Marcos, Diego}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV) 2023}, year = {2023}, } -
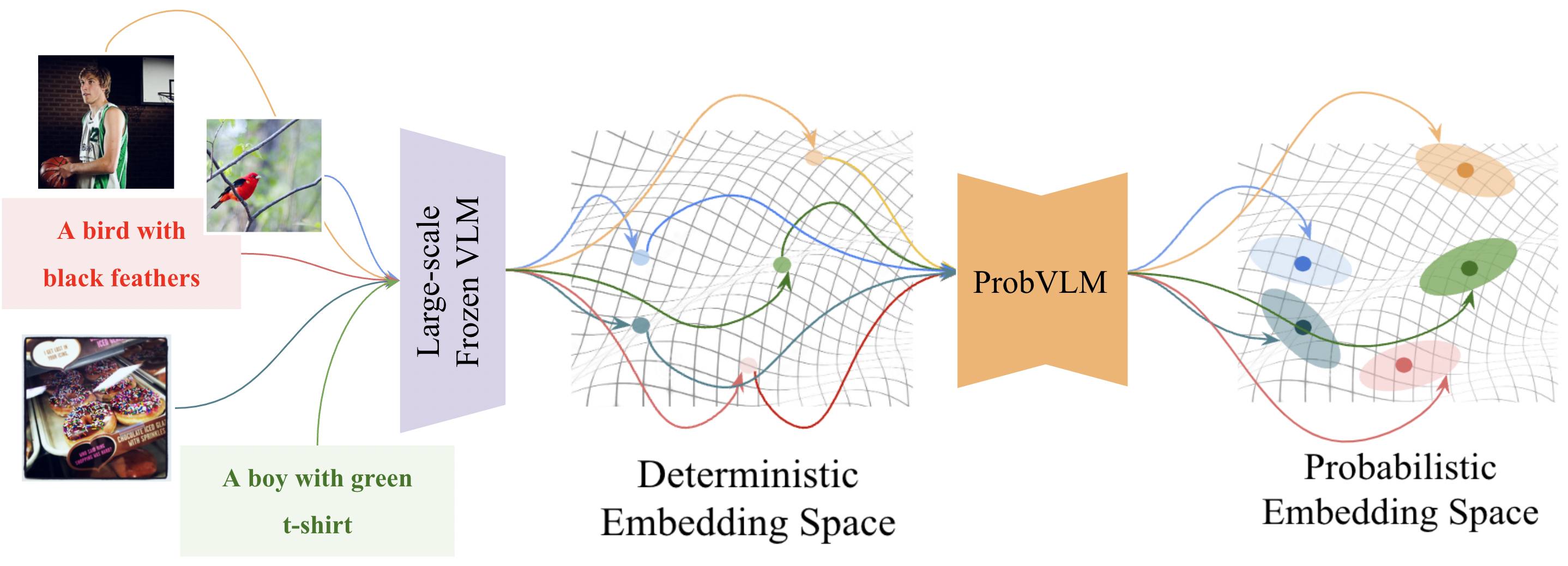 ProbVLM: Probabilistic Adapter for Frozen Vison-Language ModelsUddeshya Upadhyay , Shyamgopal Karthik , Massimiliano Mancini, and 1 more authorIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023
ProbVLM: Probabilistic Adapter for Frozen Vison-Language ModelsUddeshya Upadhyay , Shyamgopal Karthik , Massimiliano Mancini, and 1 more authorIn Proceedings of the International Conference on Computer Vision (ICCV) 2023 , Oct 2023Large-scale vision-language models (VLMs) like CLIP successfully find correspondences between images and text. Through the standard deterministic mapping process, an image or a text sample is mapped to a single vector in the embedding space. This is problematic: as multiple samples (images or text) can abstract the same concept in the physical world, deterministic embeddings do not reflect the inherent ambiguity in the embedding space. We propose ProbVLM, a probabilistic adapter that estimates probability distributions for the embeddings of pre-trained VLMs via inter/intra-modal alignment in a post-hoc manner without needing large-scale datasets or computing. On four challenging datasets, i.e., COCO, Flickr, CUB, and Oxford-flowers, we estimate the multi-modal embedding uncertainties for two VLMs, i.e., CLIP and BLIP, quantify the calibration of embedding uncertainties in retrieval tasks and show that ProbVLM outperforms other methods. Furthermore, we propose active learning and model selection as two real-world downstream tasks for VLMs and show that the estimated uncertainty aids both tasks. Lastly, we present a novel technique for visualizing the embedding distributions using a large-scale pre-trained latent diffusion model.
@inproceedings{upadhyay2023probvlm, title = {ProbVLM: Probabilistic Adapter for Frozen Vison-Language Models}, author = {Upadhyay, Uddeshya and Karthik, Shyamgopal and Mancini, Massimiliano and Akata, Zeynep}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV) 2023}, year = {2023}, } -
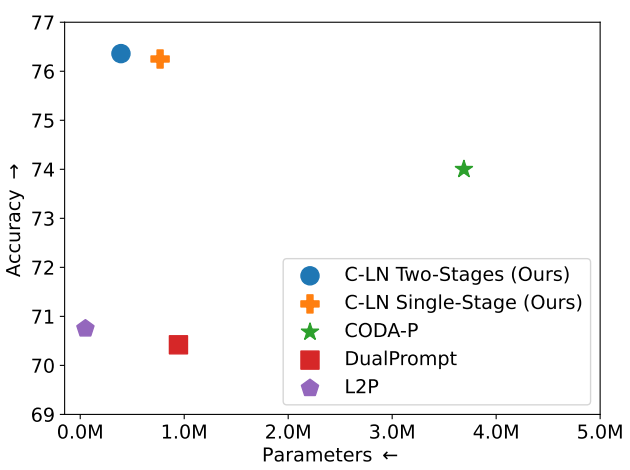 On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision TransformersThomas De Min , Massimiliano Mancini, Karteek Alahari , and 2 more authorsIn The First Workshop on Visual Continual Learning at ICCV 2023 , Oct 2023
On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision TransformersThomas De Min , Massimiliano Mancini, Karteek Alahari , and 2 more authorsIn The First Workshop on Visual Continual Learning at ICCV 2023 , Oct 2023State-of-the-art rehearsal-free continual learning methods exploit the peculiarities of Vision Transformers to learn task-specific prompts, drastically reducing catastrophic forgetting. However, there is a tradeoff between the number of learned parameters and the performance, making such models computationally expensive. In this work, we aim to reduce this cost while maintaining competitive performance. We achieve this by revisiting and extending a simple transfer learning idea: learning task-specific normalization layers. Specifically, we tune the scale and bias parameters of LayerNorm for each continual learning task, selecting them at inference time based on the similarity between task-specific keys and the output of the pre-trained model. To make the classifier robust to incorrect selection of parameters during inference, we introduce a two-stage training procedure, where we first optimize the task-specific parameters and then train the classifier with the same selection procedure of the inference time. Experiments on ImageNet-R and CIFAR-100 show that our method achieves results that are either superior or on par with the state of the art while being computationally cheaper.
@inproceedings{demin2023effectiveness, title = {On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers}, author = {De Min, Thomas and Mancini, Massimiliano and Alahari, Karteek and Alameda-Pineda, Xavier and Ricci, Elisa}, booktitle = {The First Workshop on Visual Continual Learning at ICCV 2023}, year = {2023}, }







2022
- Attention Consistency on Visual Corruptions for Single-Source Domain GeneralizationIlke Cugu , Massimiliano Mancini, Yanbei Chen , and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2022
Generalizing visual recognition models trained on a single distribution to unseen input distributions (i.e. domains) requires making them robust to superfluous correlations in the training set. In this work, we achieve this goal by altering the training images to simulate new domains and imposing consistent visual attention across the different views of the same sample. We discover that the first objective can be simply and effectively met through visual corruptions. Specifically, we alter the content of the training images using the nineteen corruptions of the ImageNet-C benchmark and three additional transformations based on Fourier transform. Since these corruptions preserve object locations, we propose an attention consistency loss to ensure that class activation maps across original and corrupted versions of the same training sample are aligned. We name our model Attention Consistency on Visual Corruptions (ACVC). We show that ACVC consistently achieves the state of the art on three single-source domain generalization benchmarks, PACS, COCO, and the large-scale DomainNet.
@inproceedings{Cugu_2022_CVPR, author = {Cugu, Ilke and Mancini, Massimiliano and Chen, Yanbei and Akata, Zeynep}, title = {Attention Consistency on Visual Corruptions for Single-Source Domain Generalization}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, month = jun, year = {2022}, } -
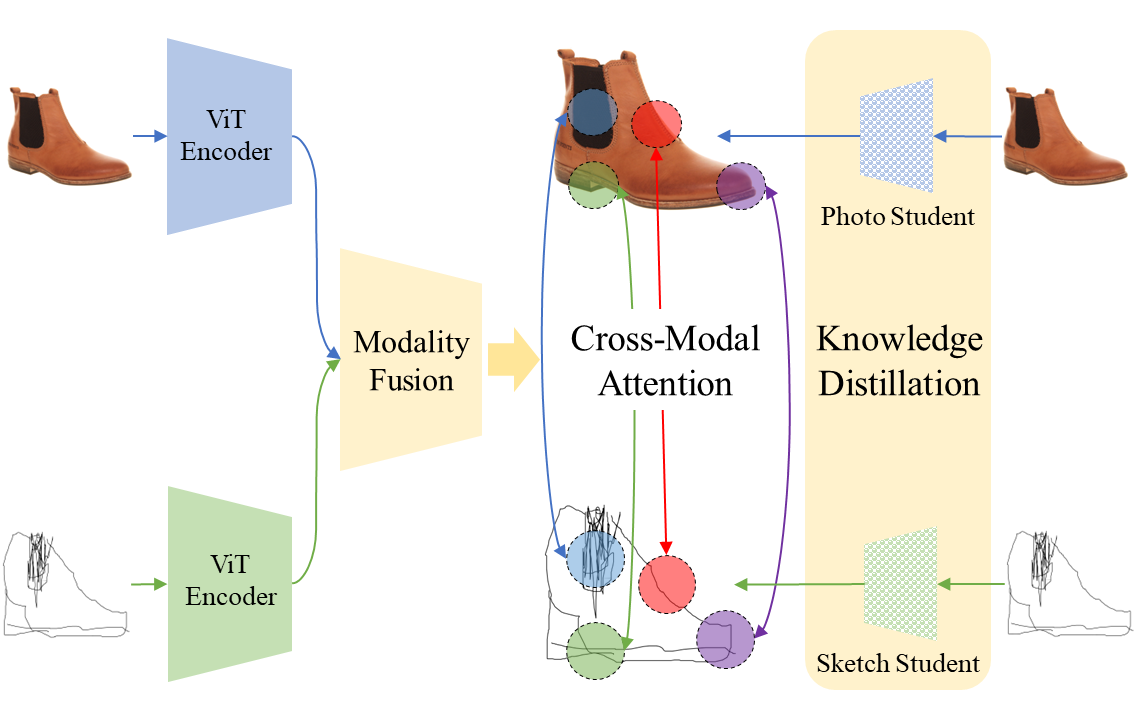 Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image RetrievalAbhra Chaudhuri , Massimiliano Mancini, Yanbei Chen , and 2 more authorsIn British Machine Vision Conference , Jun 2022
Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image RetrievalAbhra Chaudhuri , Massimiliano Mancini, Yanbei Chen , and 2 more authorsIn British Machine Vision Conference , Jun 2022Representation learning for sketch-based image retrieval has mostly been tackled by learning embeddings that discard modality-specific information. As instances from different modalities can often provide complementary information describing the underlying concept, we propose a cross-attention framework for Vision Transformers (XModalViT) that fuses modality-specific information instead of discarding them. Our framework first maps paired datapoints from the individual photo and sketch modalities to fused representations that unify information from both modalities. We then decouple the input space of the aforementioned modality fusion network into independent encoders of the individual modalities via contrastive and relational cross-modal knowledge distillation. Such encoders can then be applied to downstream tasks like cross-modal retrieval. We demonstrate the expressive capacity of the learned representations by performing a wide range of experiments and achieving state-of-the-art results on three fine-grained sketch-based image retrieval benchmarks: Shoe-V2, Chair-V2 and Sketchy.
@inproceedings{chaudhuri2022cross, title = {Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image Retrieval}, author = {Chaudhuri, Abhra and Mancini, Massimiliano and Chen, Yanbei and Akata, Zeynep and Dutta, Anjan}, booktitle = {British Machine Vision Conference}, year = {2022}, } -
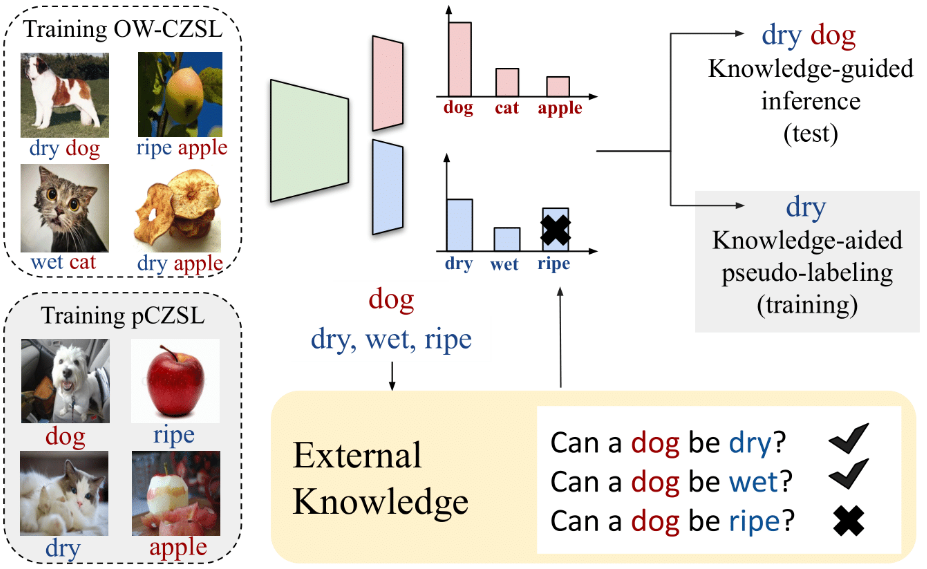 KG-SP: Knowledge Guided Simple Primitives for Open World Compositional Zero-Shot LearningShyamgopal Karthik , Massimiliano Mancini, and Zeynep AkataIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2022
KG-SP: Knowledge Guided Simple Primitives for Open World Compositional Zero-Shot LearningShyamgopal Karthik , Massimiliano Mancini, and Zeynep AkataIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2022The goal of open-world compositional zero-shot learning (OW-CZSL) is to recognize compositions of state and objects in images, given only a subset of them during training and no prior on the unseen compositions. In this setting, models operate on a huge output space, containing all possible state-object compositions. While previous works tackle the problem by learning embeddings for the compositions jointly, here we revisit a simple CZSL baseline and predict the primitives, ie states and objects, independently. To ensure that the model develops primitive-specific features, we equip the state and object classifiers with separate, non-linear feature extractors. Moreover, we estimate the feasibility of each composition through external knowledge, using this prior to remove unfeasible compositions from the output space. Finally, we propose a new setting, ie CZSL under partial supervision (pCZSL), where either only objects or state labels are available during training and we can use our prior to estimate the missing labels. Our model, Knowledge-Guided Simple Primitives (KG-SP), achieves the state of the art in both OW-CZSL and pCZSL, surpassing most recent competitors even when coupled with semi-supervised learning techniques
@inproceedings{Karthik_2022_CVPR, author = {Karthik, Shyamgopal and Mancini, Massimiliano and Akata, Zeynep}, title = {KG-SP: Knowledge Guided Simple Primitives for Open World Compositional Zero-Shot Learning}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, } -
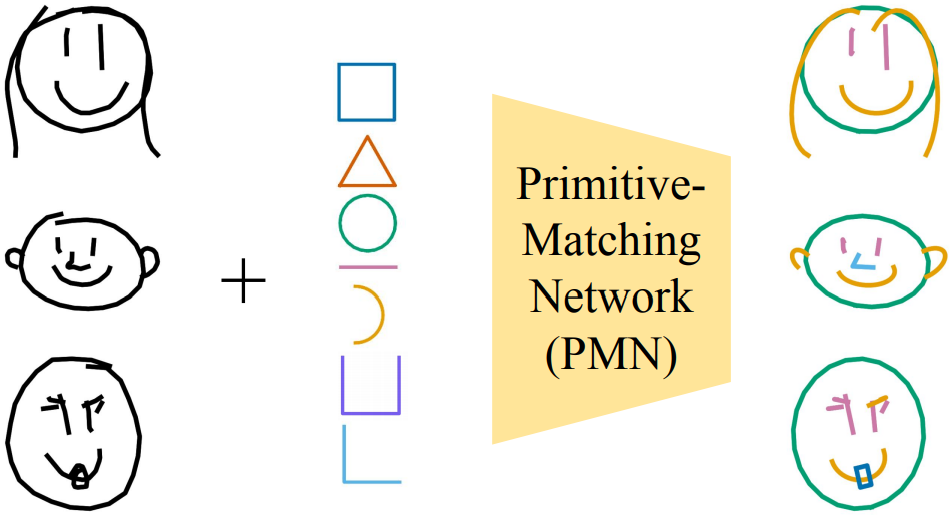 Abstracting Sketches through Simple PrimitivesStephan Alaniz , Massimiliano Mancini, Anjan Dutta , and 2 more authorsIn Proceedings of the European Conference on Computer Vision (ECCV) 2022 , Jun 2022
Abstracting Sketches through Simple PrimitivesStephan Alaniz , Massimiliano Mancini, Anjan Dutta , and 2 more authorsIn Proceedings of the European Conference on Computer Vision (ECCV) 2022 , Jun 2022Humans show high-level of abstraction capabilities in games that require quickly communicating object information. They decompose the message content into multiple parts and communicate them in an interpretable protocol. Toward equipping machines with such capabilities, we propose the Primitive-based Sketch Abstraction task where the goal is to represent sketches using a fixed set of drawing primitives under the influence of a budget. To solve this task, our PrimitiveMatching Network (PMN), learns interpretable abstractions of a sketch in a self supervised manner. Specifically, PMN maps each stroke of a sketch to its most similar primitive in a given set, predicting an affine transformation that aligns the selected primitive to the target stroke. We learn this stroke-to-primitive mapping end-to-end with a distancetransform loss that is minimal when the original sketch is precisely reconstructed with the predicted primitives. Our PMN abstraction empirically achieves the highest performance on sketch recognition and sketch-based image retrieval given a communication budget, while at the same time being highly interpretable. This opens up new possibilities for sketch analysis, such as comparing sketches by extracting the most relevant primitives that define an object category.
@inproceedings{alaniz2022abstracting, title = {Abstracting Sketches through Simple Primitives}, author = {Alaniz, Stephan and Mancini, Massimiliano and Dutta, Anjan and Marcos, Diego and Akata, Zeynep}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV) 2022}, year = {2022}, } -
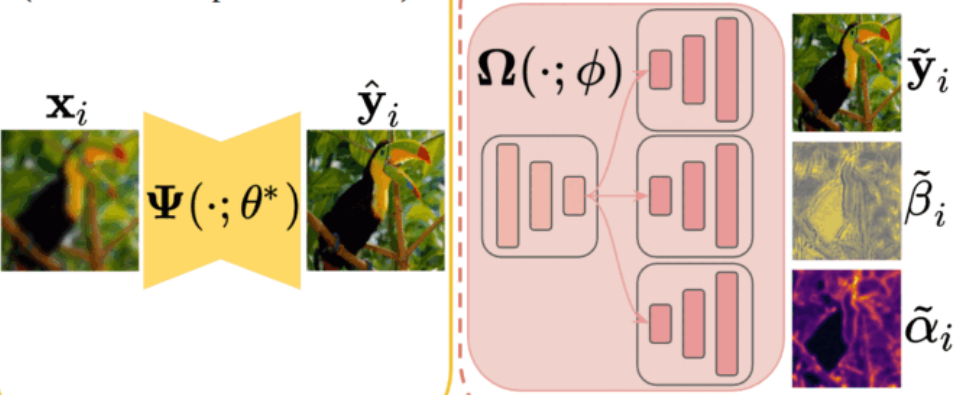 BayesCap: Bayesian Identity Cap for Calibrated Uncertainty in Frozen Neural NetworksUddeshya Upadhyay , Shyamgopal Karthik , Yanbei Chen , and 2 more authorsIn Proceedings of the European Conference on Computer Vision (ECCV) 2022 , Jun 2022
BayesCap: Bayesian Identity Cap for Calibrated Uncertainty in Frozen Neural NetworksUddeshya Upadhyay , Shyamgopal Karthik , Yanbei Chen , and 2 more authorsIn Proceedings of the European Conference on Computer Vision (ECCV) 2022 , Jun 2022High-quality calibrated uncertainty estimates are crucial for numerous real-world applications, especially for deep learning-based deployed ML systems. While Bayesian deep learning techniques allow uncertainty estimation, training them with large-scale datasets is an expensive process that does not always yield models competitive with non-Bayesian counterparts. Moreover, many of the high-performing deep learning models that are already trained and deployed are non-Bayesian in nature and do not provide uncertainty estimates. To address these issues, we propose BayesCap that learns a Bayesian identity mapping for the frozen model, allowing uncertainty estimation. BayesCap is a memory-efficient method that can be trained on a small fraction of the original dataset, enhancing pretrained non-Bayesian computer vision models by providing calibrated uncertainty estimates for the predictions without (i) hampering the performance of the model and (ii) the need for expensive retraining the model from scratch. The proposed method is agnostic to various architectures and tasks. We show the efficacy of our method on a wide variety of tasks with a diverse set of architectures, including image super-resolution, deblurring, inpainting, and crucial application such as medical image translation. Moreover, we apply the derived uncertainty estimates to detect out-of-distribution samples in critical scenarios like depth estimation in autonomous driving.
@inproceedings{upadhyay2022bayescap, title = {BayesCap: Bayesian Identity Cap for Calibrated Uncertainty in Frozen Neural Networks}, author = {Upadhyay, Uddeshya and Karthik, Shyamgopal and Chen, Yanbei and Mancini, Massimiliano and Akata, Zeynep}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV) 2022}, year = {2022}, } -
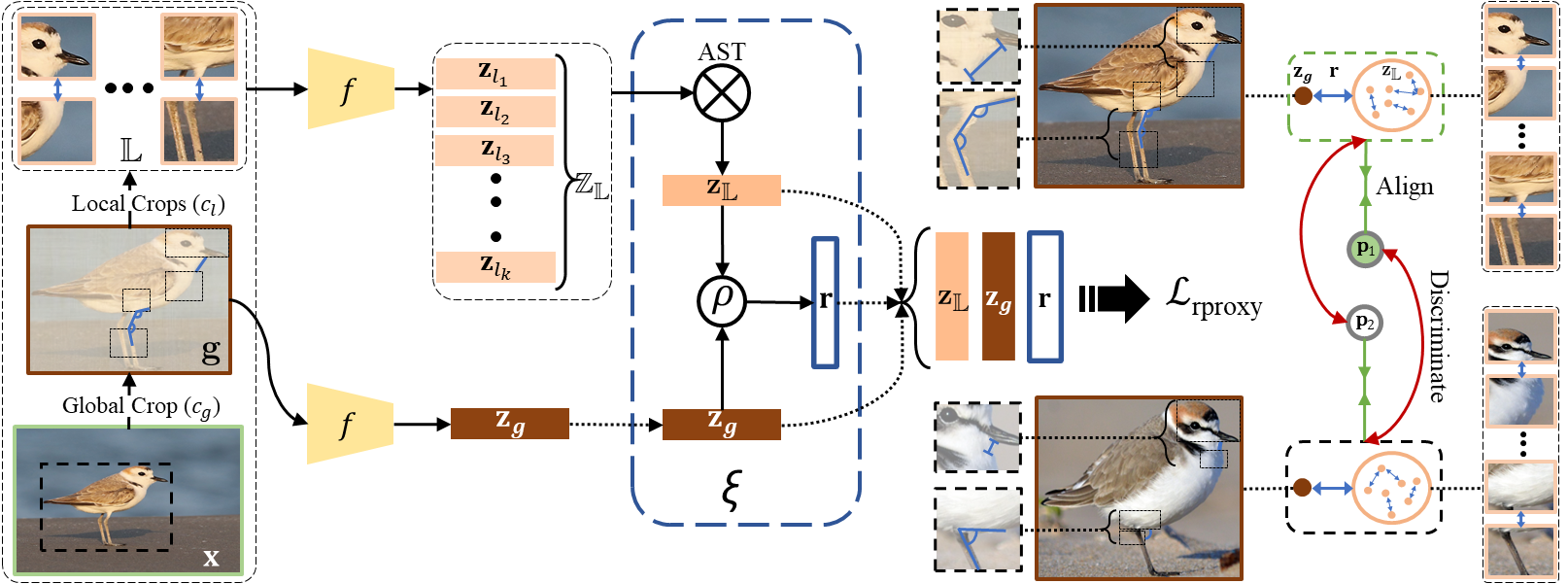 Relational Proxies: Emergent Relationships as Fine-Grained DiscriminatorsAbhra Chaudhuri , Massimiliano Mancini, Zeynep Akata , and 1 more authorAdvances in Neural Information Processing Systems (NeurIPS), Jun 2022
Relational Proxies: Emergent Relationships as Fine-Grained DiscriminatorsAbhra Chaudhuri , Massimiliano Mancini, Zeynep Akata , and 1 more authorAdvances in Neural Information Processing Systems (NeurIPS), Jun 2022Fine-grained categories that largely share the same set of parts cannot be discriminated based on part information alone, as they mostly differ in the way the local parts relate to the overall global structure of the object. We propose Relational Proxies, a novel approach that leverages the relational information between the global and local views of an object for encoding its semantic label. Starting with a rigorous formalization of the notion of distinguishability between fine-grained categories, we prove the necessary and sufficient conditions that a model must satisfy in order to learn the underlying decision boundaries in the fine-grained setting. We design Relational Proxies based on our theoretical findings and evaluate it on seven challenging fine-grained benchmark datasets and achieve state-of-the-art results on all of them, surpassing the performance of all existing works with a margin exceeding 4% in some cases. We also experimentally validate our theory on fine-grained distinguishability and obtain consistent results across multiple benchmarks.
@article{chaudhuri2022relational, title = {Relational Proxies: Emergent Relationships as Fine-Grained Discriminators}, author = {Chaudhuri, Abhra and Mancini, Massimiliano and Akata, Zeynep and Dutta, Anjan}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2022}, }






2021
-
 Prototype-based Incremental Few-Shot Semantic SegmentationFabio Cermelli , Massimiliano Mancini, Yongqin Xian , and 2 more authorsIn British Machine Vision Conference , Jun 2021
Prototype-based Incremental Few-Shot Semantic SegmentationFabio Cermelli , Massimiliano Mancini, Yongqin Xian , and 2 more authorsIn British Machine Vision Conference , Jun 2021Semantic segmentation models have two fundamental weaknesses: i) they require large training sets with costly pixel-level annotations, and ii) they have a static output space, constrained to the classes of the training set. Toward addressing both problems, we introduce a new task, Incremental Few-Shot Segmentation (iFSS). The goal of iFSS is to extend a pretrained segmentation model with new classes from few annotated images and without access to old training data. To overcome the limitations of existing models iniFSS, we propose Prototype-based Incremental Few-Shot Segmentation (PIFS) that couples prototype learning and knowledge distillation. PIFS exploits prototypes to initialize the classifiers of new classes, fine-tuning the network to refine its features representation. We design a prototype-based distillation loss on the scores of both old and new class prototypes to avoid overfitting and forgetting, and batch-renormalization to cope with non-i.i.d.few-shot data. We create an extensive benchmark for iFSS showing that PIFS outperforms several few-shot and incremental learning methods in all scenarios.
@inproceedings{cermelli2021prototype, title = {Prototype-based Incremental Few-Shot Semantic Segmentation}, author = {Cermelli, Fabio and Mancini, Massimiliano and Xian, Yongqin and Akata, Zeynep and Caputo, Barbara}, booktitle = {British Machine Vision Conference}, year = {2021}, } -
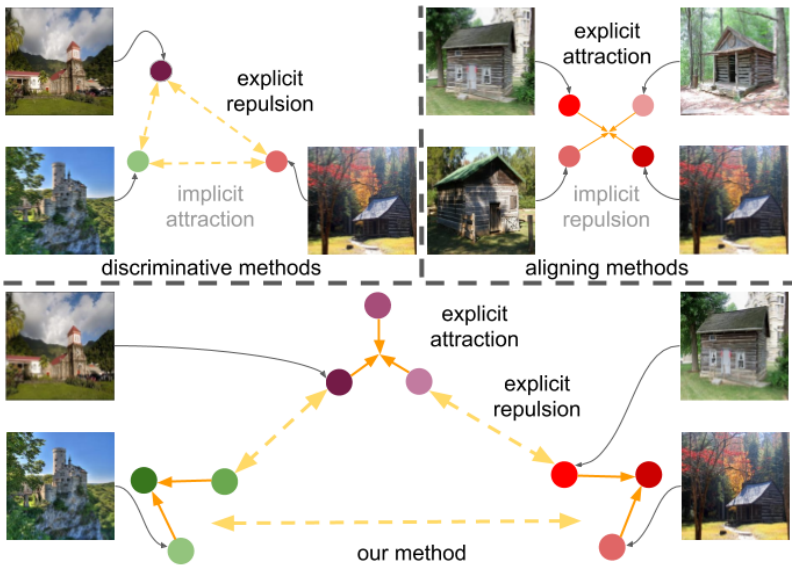 Concurrent Discrimination and Alignment for Self-Supervised Feature LearningAnjan Dutta , Massimiliano Mancini, and Zeynep AkataIn IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , Jun 2021
Concurrent Discrimination and Alignment for Self-Supervised Feature LearningAnjan Dutta , Massimiliano Mancini, and Zeynep AkataIn IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , Jun 2021Existing self-supervised learning methods learn representation by means of pretext tasks which are either (1) discriminating that explicitly specify which features should be separated or (2) aligning that precisely indicate which features should be closed together, but ignore the fact how to jointly and principally define which features to be repelled and which ones to be attracted. In this work, we combine the positive aspects of the discriminating and aligning methods, and design a hybrid method that addresses the above issue. Our method explicitly specifies the repulsion and attraction mechanism respectively by discriminative predictive task and concurrently maximizing mutual information between paired views sharing redundant information. We qualitatively and quantitatively show that our proposed model learns better features that are more effective for the diverse downstream tasks ranging from classification to semantic segmentation. Our experiments on nine established benchmarks show that the proposed model consistently outperforms the existing state-of-the-art results of self-supervised and transfer learning protocol.
@inproceedings{dutta2021concurrent, title = {Concurrent Discrimination and Alignment for Self-Supervised Feature Learning}, author = {Dutta, Anjan and Mancini, Massimiliano and Akata, Zeynep}, booktitle = {IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, pages = {2189--2198}, year = {2021}, } -
 Open World Compositional Zero-Shot LearningMassimiliano Mancini, Muhammad Ferjad Naeem , Yongqin Xian , and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2021
Open World Compositional Zero-Shot LearningMassimiliano Mancini, Muhammad Ferjad Naeem , Yongqin Xian , and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2021Compositional Zero-Shot learning (CZSL) requires to recognize state-object compositions unseen during training. In this work, instead of assuming prior knowledge about the unseen compositions, we operate in the open world setting, where the search space includes a large number of unseen compositions some of which might be unfeasible. In this setting, we start from the cosine similarity between visual features and compositional embeddings. After estimating the feasibility score of each composition, we use these scores to either directly mask the output space or as a margin for the cosine similarity between visual features and compositional embeddings during training. Our experiments on two standard CZSL benchmarks show that all the methods suffer severe performance degradation when applied in the open world setting. While our simple CZSL model achieves state-of-the-art performances in the closed world scenario, our feasibility scores boost the performance of our approach in the open world setting, clearly outperforming the previous state of the art.
@inproceedings{mancini2021open, title = {Open World Compositional Zero-Shot Learning}, author = {Mancini, Massimiliano and Naeem, Muhammad Ferjad and Xian, Yongqin and Akata, Zeynep}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2021}, } -
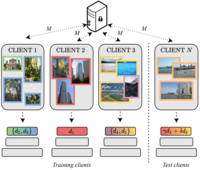 Cluster-driven Graph Federated Learning over Multiple DomainsDebora Caldarola , Massimiliano Mancini, Fabio Galasso , and 3 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2021
Cluster-driven Graph Federated Learning over Multiple DomainsDebora Caldarola , Massimiliano Mancini, Fabio Galasso , and 3 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2021Federated Learning (FL) deals with learning a central model (ie the server) in privacy-constrained scenarios, where data are stored on multiple devices (ie the clients). The central model has no direct access to the data, but only to the updates of the parameters computed locally by each client. This raises a problem, known as statistical heterogeneity, because the clients may have different data distributions (ie domains). This is only partly alleviated by clustering the clients. Clustering may reduce heterogeneity by identifying the domains, but it deprives each cluster model of the data and supervision of others. Here we propose a novel Cluster-driven Graph Federated Learning (FedCG). In FedCG, clustering serves to address statistical heterogeneity, while Graph Convolutional Networks (GCNs) enable sharing knowledge across them. FedCG: i) identifies the domains via an FL-compliant clustering and instantiates domain-specific modules (residual branches) for each domain; ii) connects the domain-specific modules through a GCN at training to learn the interactions among domains and share knowledge; and iii) learns to cluster unsupervised via teacher-student classifier-training iterations and to address novel unseen test domains via their domain soft-assignment scores. Thanks to the unique interplay of GCN over clusters, FedCG achieves the state-of-the-art on multiple FL benchmarks.
@inproceedings{caldarola2021cluster, author = {Caldarola, Debora and Mancini, Massimiliano and Galasso, Fabio and Ciccone, Marco and Rodolà, Emanuele and Caputo, Barbara}, title = {Cluster-driven Graph Federated Learning over Multiple Domains}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, year = {2021}, } -
 Detecting Anomalies in Semantic Segmentation with PrototypesDario Fontanel , Fabio Cermelli , Massimiliano Mancini, and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2021
Detecting Anomalies in Semantic Segmentation with PrototypesDario Fontanel , Fabio Cermelli , Massimiliano Mancini, and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2021Traditional semantic segmentation methods can recognize at test time only the classes that are present in the training set. This is a significant limitation, especially for semantic segmentation algorithms mounted on intelligent autonomous systems, deployed in realistic settings. Regardless of how many classes the system has seen at training time, it is inevitable that unexpected, unknown objects will appear at test time. The failure in identifying such anomalies may lead to incorrect, even dangerous behaviors of the autonomous agent equipped with such segmentation model when deployed in the real world. Current state of the art of anomaly segmentation uses generative models, exploiting their incapability to reconstruct patterns unseen during training. However, training these models is expensive, and their generated artifacts may create false anomalies. In this paper we take a different route and we propose to address anomaly segmentation through prototype learning. Our intuition is that anomalous pixels are those that are dissimilar to all class prototypes known by the model. We extract class prototypes from the training data in a lightweight manner using a cosine similarity-based classifier. Experiments on StreetHazards show that our approach achieves the new state of the art, with a significant margin over previous works, despite the reduced computational overhead.
@inproceedings{fontanel2021detecting, author = {Fontanel, Dario and Cermelli, Fabio and Mancini, Massimiliano and Caputo, Barbara}, title = {Detecting Anomalies in Semantic Segmentation with Prototypes}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, year = {2021}, } -
 A Closer Look at Self-training for Zero-Label Semantic SegmentationGiuseppe Pastore , Fabio Cermelli , Yongqin Xian , and 3 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2021
A Closer Look at Self-training for Zero-Label Semantic SegmentationGiuseppe Pastore , Fabio Cermelli , Yongqin Xian , and 3 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , Jun 2021Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.
@inproceedings{pastore2021closer, author = {Pastore, Giuseppe and Cermelli, Fabio and Xian, Yongqin and Mancini, Massimiliano and Akata, Zeynep and Caputo, Barbara}, title = {A Closer Look at Self-training for Zero-Label Semantic Segmentation}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, year = {2021}, } -
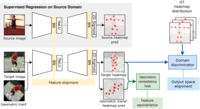 Shape Consistent 2D Keypoint Estimation under Domain ShiftLevi O. Vasconcelos , Massimiliano Mancini, Davide Boscaini , and 3 more authorsIn 2020 25th International Conference on Pattern Recognition (ICPR) , Jun 2021
Shape Consistent 2D Keypoint Estimation under Domain ShiftLevi O. Vasconcelos , Massimiliano Mancini, Davide Boscaini , and 3 more authorsIn 2020 25th International Conference on Pattern Recognition (ICPR) , Jun 2021Recent unsupervised domain adaptation methods based on deep architectures have shown remarkable performance not only in traditional classification tasks but also in more complex problems involving structured predictions (e.g. semantic segmentation, depth estimation). Following this trend, in this paper we present a novel deep adaptation framework for estimating keypoints under domain shift, i.e, when the training (source) and the test (target) images significantly differ in terms of visual appearance. Our method seamlessly combines three different components: feature alignment, adversarial training and self-supervision. Specifically, our deep architecture leverages from domain-specific distribution alignment layers to perform target adaptation at the feature level. Furthermore, a novel loss is proposed which combines an adversarial term for ensuring aligned predictions in the output space and a geometric consistency term which guarantees coherent predictions between a target sample and its perturbed version. Our extensive experimental evaluation conducted on three publicly available benchmarks shows that our approach outperforms state-of-the-art domain adaptation methods in the 2D keypoint prediction task.
@inproceedings{vasconcelos2020shape, author = {Vasconcelos, Levi O. and Mancini, Massimiliano and Boscaini, Davide and Bulò, Samuel Rota and Caputo, Barbara and Ricci, Elisa}, booktitle = {2020 25th International Conference on Pattern Recognition (ICPR)}, title = {Shape Consistent 2D Keypoint Estimation under Domain Shift}, year = {2021}, pages = {8037-8044}, } -
 Inferring Latent Domains for Unsupervised Deep Domain AdaptationMassimiliano Mancini, Lorenzo Porzi , Samuel Rota Buló , and 2 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence, Jun 2021
Inferring Latent Domains for Unsupervised Deep Domain AdaptationMassimiliano Mancini, Lorenzo Porzi , Samuel Rota Buló , and 2 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence, Jun 2021Unsupervised Domain Adaptation (UDA) refers to the problem of learning a model in a target domain where labeled data are not available by leveraging information from annotated data in a source domain. Most deep UDA approaches operate in a single-source, single-target scenario, i.e., they assume that the source and the target samples arise from a single distribution. However, in practice most datasets can be regarded as mixtures of multiple domains. In these cases, exploiting traditional single-source, single-target methods for learning classification models may lead to poor results. Furthermore, it is often difficult to provide the domain labels for all data points, i.e. latent domains should be automatically discovered. This paper introduces a novel deep architecture which addresses the problem of UDA by automatically discovering latent domains in visual datasets and exploiting this information to learn robust target classifiers. Specifically, our architecture is based on two main components, i.e. a side branch that automatically computes the assignment of each sample to its latent domain and novel layers that exploit domain membership information to appropriately align the distribution of the CNN internal feature representations to a reference distribution. We evaluate our approach on publicly available benchmarks, showing that it outperforms state-of-the-art domain adaptation methods.
@article{mancini2021inferring, author = {Mancini, Massimiliano and Porzi, Lorenzo and Buló, Samuel Rota and Caputo, Barbara and Ricci, Elisa}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, title = {Inferring Latent Domains for Unsupervised Deep Domain Adaptation}, year = {2021}, volume = {43}, number = {2}, pages = {485-498}, doi = {10.1109/TPAMI.2019.2933829}, } -
 Modeling the Background for Incremental and Weakly-Supervised Semantic SegmentationFabio Cermelli , Massimiliano Mancini, Samuel Rota Bulò , and 2 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence, Jun 2021
Modeling the Background for Incremental and Weakly-Supervised Semantic SegmentationFabio Cermelli , Massimiliano Mancini, Samuel Rota Bulò , and 2 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence, Jun 2021Deep neural networks have enabled major progresses in semantic segmentation. However, even the most advanced neural architectures suffer from important limitations. First, they are vulnerable to catastrophic forgetting, i.e., they perform poorly when they are required to incrementally update their model as new classes are available. Second, they rely on large amount of pixel-level annotations to produce accurate segmentation maps. To tackle these issues, we introduce a novel incremental class learning approach for semantic segmentation taking into account a peculiar aspect of this task: since each training step provides annotation only for a subset of all possible classes, pixels of the background class exhibit a semantic shift. Therefore, we revisit the traditional distillation paradigm by designing novel loss terms which explicitly account for the background shift. Additionally, we introduce a novel strategy to initialize classifier’s parameters at each step in order to prevent biased predictions toward the background class. Finally, we demonstrate that our approach can be extended to point- and scribble-based weakly supervised segmentation, modeling the partial annotations to create priors for unlabeled pixels. We demonstrate the effectiveness of our approach with an extensive evaluation on the Pascal-VOC, ADE20K, and Cityscapes datasets, significantly outperforming state-of-the-art methods.
@article{cermelli2021modeling, title = {Modeling the Background for Incremental and Weakly-Supervised Semantic Segmentation}, author = {Cermelli, Fabio and Mancini, Massimiliano and Bulò, Samuel Rota and Ricci, Elisa and Caputo, Barbara}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, year = {2021}, publisher = {IEEE}, } -
 On the Challenges of Open World Recognition Under Shifting Visual DomainsDario Fontanel , Fabio Cermelli , Massimiliano Mancini, and 1 more authorIEEE Robotics and Automation Letters, Jun 2021
On the Challenges of Open World Recognition Under Shifting Visual DomainsDario Fontanel , Fabio Cermelli , Massimiliano Mancini, and 1 more authorIEEE Robotics and Automation Letters, Jun 2021Robotic visual systems operating in the wild must act in unconstrained scenarios, under different environmental conditions while facing a variety of semantic concepts, including unknown ones. To this end, recent works tried to empower visual object recognition methods with the capability to i) detect unseen concepts and ii) extended their knowledge over time, as images of new semantic classes arrive. This setting, called Open World Recognition (OWR), has the goal to produce systems capable of breaking the semantic limits present in the initial training set. However, this training set imposes to the system not only its own semantic limits, but also environmental ones, due to its bias toward certain acquisition conditions that do not necessarily reflect the high variability of the real-world. This discrepancy between training and test distribution is called domain-shift. This work investigates whether OWR algorithms are effective under domain-shift, presenting the first benchmark setup for assessing fairly the performances of OWR algorithms, with and without domain-shift. We then use this benchmark to conduct analyses in various scenarios, showing how existing OWR algorithms indeed suffer a severe performance degradation when train and test distributions differ. Our analysis shows that this degradation is only slightly mitigated by coupling OWR with domain generalization techniques, indicating that the mere plug-and-play of existing algorithms is not enough to recognize new and unknown categories in unseen domains. Our results clearly point toward open issues and future research directions, that need to be investigated for building robot visual systems able to function reliably under these challenging yet very real conditions.
@article{fontanel2021challenges, author = {Fontanel, Dario and Cermelli, Fabio and Mancini, Massimiliano and Caputo, Barbara}, journal = {IEEE Robotics and Automation Letters}, title = {On the Challenges of Open World Recognition Under Shifting Visual Domains}, year = {2021}, volume = {6}, number = {2}, pages = {604-611}, } -
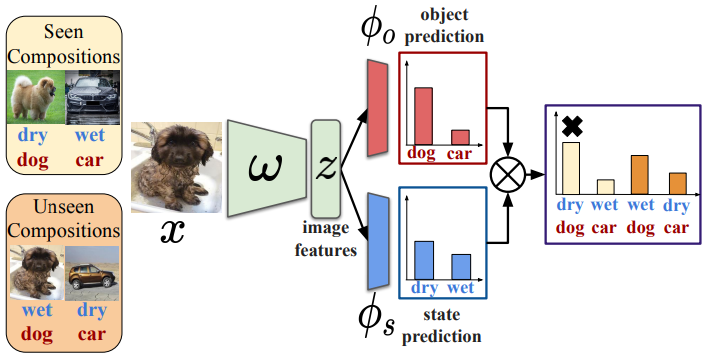 Revisiting Visual Product for Compositional Zero-Shot LearningShyamgopal Karthik , Massimiliano Mancini, and Zeynep AkataIn NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications , Jun 2021
Revisiting Visual Product for Compositional Zero-Shot LearningShyamgopal Karthik , Massimiliano Mancini, and Zeynep AkataIn NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications , Jun 2021Compositional Zero-Shot Learning (CZSL) aims to recognize compositions of objects and states in images, and generalize to the unseen compositions of objects and states. Recent works tackled this problem effectively by using side information (e.g., word embeddings) together with either consistency constraints or specific network designs modeling the relationships between objects, states, compositions, and visual features. In this work, we take a step back, and we revisit the simplest baseline for this task, i.e., Visual Product (VisProd). VisProd considers CZSL as a multi-task problem, predicting objects and states separately. Despite its appealing simplicity, this baseline showed low performance in early CZSL studies. Here we identify the two main reasons behind such unimpressive initial results: network capacity and bias on the seen classes. We show that simple modifications to the object and state predictors allow the model to achieve either comparable or superior results w.r.t. the recent state of the art in both the open-world and closed-world CZSL settings on three different benchmarks.
@inproceedings{karthik2021revisiting, title = {Revisiting Visual Product for Compositional Zero-Shot Learning}, author = {Karthik, Shyamgopal and Mancini, Massimiliano and Akata, Zeynep}, booktitle = {NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications}, year = {2021}, }











2020
-
 Modeling the Background for Incremental Learning in Semantic SegmentationFabio Cermelli , Massimiliano Mancini, Samuel Rota Bulò , and 2 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2020
Modeling the Background for Incremental Learning in Semantic SegmentationFabio Cermelli , Massimiliano Mancini, Samuel Rota Bulò , and 2 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2020Despite their effectiveness in a wide range of tasks, deep architectures suffer from some important limitations. In particular, they are vulnerable to catastrophic forgetting, ie they perform poorly when they are required to update their model as new classes are available but the original training set is not retained. This paper addresses this problem in the context of semantic segmentation. Current strategies fail on this task because they do not consider a peculiar aspect of semantic segmentation: since each training step provides annotation only for a subset of all possible classes, pixels of the background class (ie pixels that do not belong to any other classes) exhibit a semantic distribution shift. In this work we revisit classical incremental learning methods, proposing a new distillation-based framework which explicitly accounts for this shift. Furthermore, we introduce a novel strategy to initialize classifier’s parameters, thus preventing biased predictions toward the background class. We demonstrate the effectiveness of our approach with an extensive evaluation on the Pascal-VOC 2012 and ADE20K datasets, significantly outperforming state of the art incremental learning methods.
@inproceedings{Cermelli_2020_CVPR, author = {Cermelli, Fabio and Mancini, Massimiliano and Bulò, Samuel Rota and Ricci, Elisa and Caputo, Barbara}, title = {Modeling the Background for Incremental Learning in Semantic Segmentation}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2020}, } -
 Towards Recognizing Unseen Categories in Unseen DomainsMassimiliano Mancini, Zeynep Akata , Elisa Ricci , and 1 more authorIn European Conference on Computer Vision (ECCV) , Jun 2020
Towards Recognizing Unseen Categories in Unseen DomainsMassimiliano Mancini, Zeynep Akata , Elisa Ricci , and 1 more authorIn European Conference on Computer Vision (ECCV) , Jun 2020Current deep visual recognition systems suffer from severe performance degradation when they encounter new images from classes and scenarios unseen during training. Hence, the core challenge of Zero-Shot Learning (ZSL) is to cope with the semantic-shift whereas the main challenge of Domain Adaptation and Domain Generalization (DG) is the domain-shift. While historically ZSL and DG tasks are tackled in isolation, this work develops with the ambitious goal of solving them jointly, i.e. by recognizing unseen visual concepts in unseen domains. We present CuMix (Curriculum Mixup for recognizing unseen categories in unseen domains), a holistic algorithm to tackle ZSL, DG and ZSL+DG. The key idea of CuMix is to simulate the test-time domain and semantic shift using images and features from unseen domains and categories generated by mixing up the multiple source domains and categories available during training. Moreover, a curriculum-based mixing policy is devised to generate increasingly complex training samples. Results on standard ZSL and DG datasets and on ZSL+DG using the DomainNet benchmark demonstrate the effectiveness of our approach.
@inproceedings{mancini2020towards, author = {Mancini, Massimiliano and Akata, Zeynep and Ricci, Elisa and Caputo, Barbara}, title = {Towards Recognizing Unseen Categories in Unseen Domains}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2020}, } -
 Boosting binary masks for multi-domain learning through affine transformationsMassimiliano Mancini, Elisa Ricci , Barbara Caputo , and 1 more authorMachine Vision and Applications, Jun 2020
Boosting binary masks for multi-domain learning through affine transformationsMassimiliano Mancini, Elisa Ricci , Barbara Caputo , and 1 more authorMachine Vision and Applications, Jun 2020In this work, we present a new, algorithm for multi-domain learning. Given a pretrained architecture and a set of visual domains received sequentially, the goal of multi-domain learning is to produce a single model performing a task in all the domains together. Recent works showed how we can address this problem by masking the internal weights of a given original conv-net through learned binary variables. In this work, we provide a general formulation of binary mask based models for multi-domain learning by affine transformations of the original network parameters. Our formulation obtains significantly higher levels of adaptation to new domains, achieving performances comparable to domain-specific models while requiring slightly more than 1 bit per network parameter per additional domain. Experiments on two popular benchmarks showcase the power of our approach, achieving performances close to state-of-the-art methods on the Visual Decathlon Challenge.
@article{mancini2020boosting, title = {Boosting binary masks for multi-domain learning through affine transformations}, author = {Mancini, Massimiliano and Ricci, Elisa and Caputo, Barbara and Bulò, Samuel Rota}, journal = {Machine Vision and Applications}, volume = {31}, number = {6}, pages = {1--14}, year = {2020}, publisher = {Springer}, } -
 Boosting Deep Open World Recognition by ClusteringDario Fontanel , Fabio Cermelli , Massimiliano Mancini, and 3 more authorsIEEE Robotics and Automation Letters, Jun 2020
Boosting Deep Open World Recognition by ClusteringDario Fontanel , Fabio Cermelli , Massimiliano Mancini, and 3 more authorsIEEE Robotics and Automation Letters, Jun 2020While convolutional neural networks have brought significant advances in robot vision, their ability is often limited to closed world scenarios, where the number of semantic concepts to be recognized is determined by the available training set. Since it is practically impossible to capture all possible semantic concepts present in the real world in a single training set, we need to break the closed world assumption, equipping our robot with the capability to act in an open world. To provide such ability, a robot vision system should be able to (i) identify whether an instance does not belong to the set of known categories (i.e. open set recognition), and (ii) extend its knowledge to learn new classes over time (i.e. incremental learning). In this work, we show how we can boost the performance of deep open world recognition algorithms by means of a new loss formulation enforcing a global to local clustering of class-specific features. In particular, a first loss term, i.e. global clustering, forces the network to map samples closer to the class centroid they belong to while the second one, local clustering, shapes the representation space in such a way that samples of the same class get closer in the representation space while pushing away neighbours belonging to other classes. Moreover, we propose a strategy to learn class-specific rejection thresholds, instead of heuristically estimating a single global threshold, as in previous works. Experiments on RGB-D Object and Core50 datasets show the effectiveness of our approach.
@article{fontanel2020boosting, author = {Fontanel, Dario and Cermelli, Fabio and Mancini, Massimiliano and Bulò, Samuel Rota and Ricci, Elisa and Caputo, Barbara}, journal = {IEEE Robotics and Automation Letters}, title = {Boosting Deep Open World Recognition by Clustering}, year = {2020}, volume = {5}, number = {4}, pages = {5985-5992}, } -
 Towards Recognizing New Semantic Concepts in New Visual DomainsMassimiliano ManciniSapienza University of Rome , Jun 2020
Towards Recognizing New Semantic Concepts in New Visual DomainsMassimiliano ManciniSapienza University of Rome , Jun 2020Deep learning models heavily rely on large scale annotated datasets for training. Unfortunately, datasets cannot capture the infinite variability of the real world, thus neural networks are inherently limited by the restricted visual and semantic information contained in their training set. In this thesis, we argue that it is crucial to design deep architectures that can operate in previously unseen visual domains and recognize novel semantic concepts. In the first part of the thesis, we describe different solutions to enable deep models to generalize to new visual domains, by transferring knowledge from a labeled source domain(s) to a domain (target) where no labeled data are available. We will show how variants of batch-normalization (BN) can be applied to different scenarios, from domain adaptation when source and target are mixtures of multiple latent domains, to domain generalization, continuous domain adaptation, and predictive domain adaptation, where information about the target domain is available only in the form of metadata. In the second part of the thesis, we show how to extend the knowledge of a pretrained deep model to new semantic concepts, without access to the original training set. We address the scenarios of sequential multi-task learning, using transformed task-specific binary masks, open-world recognition, with end-to-end training and enforced clustering, and incremental class learning in semantic segmentation, where we highlight and address the problem of the semantic shift of the background class. In the final part, we tackle a more challenging problem: given images of multiple domains and semantic categories (with their attributes), how to build a model that recognizes images of unseen concepts in unseen domains? We also propose an approach based on domain and semantic mixing of inputs and features, which is a first, promising step towards solving this problem.
@phdthesis{mancini2020phd, title = {Towards Recognizing New Semantic Concepts in New Visual Domains}, school = {Sapienza University of Rome}, author = {Mancini, Massimiliano}, year = {2020}, }





2019
-
 Structured Domain Adaptation for 3D Keypoint EstimationLevi O Vasconcelos , Massimiliano Mancini, Davide Boscaini , and 2 more authorsIn 2019 International Conference on 3D Vision (3DV) , Jun 2019
Structured Domain Adaptation for 3D Keypoint EstimationLevi O Vasconcelos , Massimiliano Mancini, Davide Boscaini , and 2 more authorsIn 2019 International Conference on 3D Vision (3DV) , Jun 2019Motivated by recent advances in deep domain adaptation, this paper introduces a deep architecture for estimating 3D keypoints when the training (source) and the test (target) images greatly differ in terms of visual appearance (domain shift). Our approach operates by promoting domain distribution alignment in the feature space adopting batch normalization-based techniques. Furthermore, we propose to collect statistics about 3D keypoints positions of the source training data and to use this prior information to constrain predictions on the target domain introducing a loss derived from Multidimensional Scaling. We conduct an extensive experimental evaluation considering three publicly available benchmarks and show that our approach out-performs state-of-the-art domain adaptation methods for 3D keypoints predictions.
@inproceedings{vasconcelos2019structured, title = {Structured Domain Adaptation for 3D Keypoint Estimation}, author = {Vasconcelos, Levi O and Mancini, Massimiliano and Boscaini, Davide and Caputo, Barbara and Ricci, Elisa}, booktitle = {2019 International Conference on 3D Vision (3DV)}, year = {2019}, organization = {IEEE}, } -
 Discovering Latent Domains for Unsupervised Domain Adaptation Through ConsistencyMassimiliano Mancini, Lorenzo Porzi , Fabio Cermelli , and 1 more authorJun 2019
Discovering Latent Domains for Unsupervised Domain Adaptation Through ConsistencyMassimiliano Mancini, Lorenzo Porzi , Fabio Cermelli , and 1 more authorJun 2019In recent years, great advances in Domain Adaptation (DA) have been possible through deep neural networks. While this is true even for multi-source scenarios, most of the methods are based on the assumption that the domain to which each sample belongs is known a priori. However, in practice, we might have a source domain composed by a mixture of multiple sub-domains, without any prior about the sub-domain to which each source sample belongs. In this case, while multi-source DA methods are not applicable, restoring to single-source ones may lead to sub-optimal results. In this work, we explore a recent direction in deep domain adaptation: automatically discovering latent domains in visual datasets. Previous works address this problem by using a domain prediction branch, trained with an entropy loss. Here we present a novel formulation for training the domain prediction branch which exploits (i) domain prediction output for various perturbations of the input features and (ii) the min-entropy consensus loss, which forces the predictions of the perturbation to be both consistent and with low entropy. We compare our approach to the previous state-of-the-art on publicly-available datasets, showing the effectiveness of our method both quantitatively and qualitatively.
@article{mancini2019discovering, title = {Discovering Latent Domains for Unsupervised Domain Adaptation Through Consistency}, author = {Mancini, Massimiliano and Porzi, Lorenzo and Cermelli, Fabio and Caputo, Barbara}, booktitle = {International Conference on Image Analysis and Processing (ICIAP)}, year = {2019}, } -
 Knowledge is Never Enough: Towards Web Aided Deep Open World RecognitionMassimilano Mancini , Hakan Karaoguz , Elisa Ricci , and 2 more authorsIn IEEE International Conference on Robotics and Automation (ICRA) , May 2019
Knowledge is Never Enough: Towards Web Aided Deep Open World RecognitionMassimilano Mancini , Hakan Karaoguz , Elisa Ricci , and 2 more authorsIn IEEE International Conference on Robotics and Automation (ICRA) , May 2019While today’s robots are able to perform sophisticated tasks, they can only act on objects they have been trained to recognize. This is a severe limitation: any robot will inevitably see new objects in unconstrained settings, and thus will always have visual knowledge gaps. However, standard visual modules are usually built on a limited set of classes and are based on the strong prior that an object must belong to one of those classes. Identifying whether an instance does not belong to the set of known categories (i.e. open set recognition), only partially tackles this problem, as a truly autonomous agent should be able not only to detect what it does not know, but also to extend dynamically its knowledge about the world. We contribute to this challenge with a deep learning architecture that can dynamically update its known classes in an end-to-end fashion. The proposed deep network, based on a deep extension of a non-parametric model, detects whether a perceived object belongs to the set of categories known by the system and learns it without the need to retrain the whole system from scratch. Annotated images about the new category can be provided by an ‘oracle’ (i.e. human supervision), or by autonomous mining of the Web. Experiments on two different databases and on a robot platform demonstrate the promise of our approach.
@inproceedings{mancini2019knowledge, author = {Mancini, Massimilano and Karaoguz, Hakan and Ricci, Elisa and Jensfelt, Patric and Caputo, Barbara}, title = {Knowledge is Never Enough: Towards Web Aided Deep Open World Recognition}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2019}, month = may, } -
 Adagraph: Unifying predictive and continuous domain adaptation through graphsMassimiliano Mancini, Samuel Rota Bulò , Barbara Caputo , and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition , May 2019
Adagraph: Unifying predictive and continuous domain adaptation through graphsMassimiliano Mancini, Samuel Rota Bulò , Barbara Caputo , and 1 more authorIn IEEE/CVF Conference on Computer Vision and Pattern Recognition , May 2019The ability to categorize is a cornerstone of visual intelligence, and a key functionality for artificial, autonomous visual machines. This problem will never be solved without algorithms able to adapt and generalize across visual domains. Within the context of domain adaptation and generalization, this paper focuses on the predictive domain adaptation scenario, namely the case where no target data are available and the system has to learn to generalize from annotated source images plus unlabeled samples with associated metadata from auxiliary domains. Our contribution is the first deep architecture that tackles predictive domain adaptation, able to leverage over the information brought by the auxiliary domains through a graph. Moreover, we present a simple yet effective strategy that allows us to take advantage of the incoming target data at test time, in a continuous domain adaptation scenario. Experiments on three benchmark databases support the value of our approach.
@inproceedings{mancini2019adagraph, title = {Adagraph: Unifying predictive and continuous domain adaptation through graphs}, author = {Mancini, Massimiliano and Bulò, Samuel Rota and Caputo, Barbara and Ricci, Elisa}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {6568--6577}, year = {2019}, }




2018
- Boosting Domain Adaptation by Discovering Latent DomainsMassimilano Mancini , Lorenzo Porzi , Samuel Rota Bulò , and 2 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , May 2018
Current Domain Adaptation (DA) methods based on deep architectures assume that the source samples arise from a single distribution. However, in practice most datasets can be regarded as mixtures of multiple domains. In these cases exploiting single-source DA methods for learning target classifiers may lead to sub-optimal, if not poor, results. In addition, in many applications it is difficult to manually provide the domain labels for all source data points, ie latent domains should be automatically discovered. This paper introduces a novel Convolutional Neural Network (CNN) architecture which (i) automatically discovers latent domains in visual datasets and (ii) exploits this information to learn robust target classifiers. Our approach is based on the introduction of two main components, which can be embedded into any existing CNN architecture:(i) a side branch that automatically computes the assignment of a source sample to a latent domain and (ii) novel layers that exploit domain membership information to appropriately align the distribution of the CNN internal feature representations to a reference distribution. We test our approach on publicly-available datasets, showing that it outperforms state-of-the-art multi-source DA methods by a large margin.
@inproceedings{mancini2018boosting, author = {Mancini, Massimilano and Porzi, Lorenzo and Rota Bulò, Samuel and Caputo, Barbara and Ricci, Elisa}, title = {Boosting Domain Adaptation by Discovering Latent Domains}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2018}, } -
 Best sources forward: domain generalization through source-specific netsMassimilano Mancini , Samuel Rota Bulò , Barbara Caputo , and 1 more authorIn IEEE International Conference on Image Processing (ICIP) , Oct 2018
Best sources forward: domain generalization through source-specific netsMassimilano Mancini , Samuel Rota Bulò , Barbara Caputo , and 1 more authorIn IEEE International Conference on Image Processing (ICIP) , Oct 2018A long standing problem in visual object categorization is the ability of algorithms to generalize across different testing conditions. The problem has been formalized as a covariate shift among the probability distributions generating the training data (source) and the test data (target) and several domain adaptation methods have been proposed to address this issue. While these approaches have considered the single source-single target scenario, it is plausible to have multiple sources and require adaptation to any possible target domain. This last scenario, named Domain Generalization (DG), is the focus of our work. Differently from previous DG methods which learn domain invariant representations from source data, we design a deep network with multiple domain-specific classifiers, each associated to a source domain. At test time we estimate the probabilities that a target sample belongs to each source domain and exploit them to optimally fuse the classifiers predictions. To further improve the generalization ability of our model, we also introduced a domain agnostic component supporting the final classifier. Experiments on two public benchmarks demonstrate the power of our approach.
@inproceedings{mancini2018best, author = {Mancini, Massimilano and Rota Bulò, Samuel and Caputo, Barbara and Ricci, Elisa}, title = {Best sources forward: domain generalization through source-specific nets}, booktitle = {IEEE International Conference on Image Processing (ICIP)}, year = {2018}, month = oct, } -
 Kitting in the Wild through Online Domain AdaptationMassimilano Mancini , Hakan Karaoguz , Elisa Ricci , and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , Oct 2018
Kitting in the Wild through Online Domain AdaptationMassimilano Mancini , Hakan Karaoguz , Elisa Ricci , and 2 more authorsIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , Oct 2018Technological developments call for increasing perception and action capabilities of robots. Among other skills, vision systems that can adapt to any possible change in the working conditions are needed. Since these conditions are unpredictable, we need benchmarks which allow to assess the generalization and robustness capabilities of our visual recognition algorithms. In this work we focus on robotic kitting in unconstrained scenarios. As a first contribution, we present a new visual dataset for the kitting task. Differently from standard object recognition datasets, we provide images of the same objects acquired under various conditions where camera, illumination and background are changed. This novel dataset allows for testing the robustness of robot visual recognition algorithms to a series of different domain shifts both in isolation and unified. Our second contribution is a novel online adaptation algorithm for deep models, based on batch-normalization layers, which allows to continuously adapt a model to the current working conditions. Differently from standard domain adaptation algorithms, it does not require any image from the target domain at training time. We benchmark the performance of the algorithm on the proposed dataset, showing its capability to fill the gap between the performances of a standard architecture and its counterpart adapted offline to the given target domain.
@inproceedings{mancini2018kitting, author = {Mancini, Massimilano and Karaoguz, Hakan and Ricci, Elisa and Jensfelt, Patric and Caputo, Barbara}, title = {Kitting in the Wild through Online Domain Adaptation}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2018}, month = oct, } -
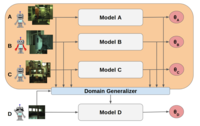 Robust Place Categorization With Deep Domain GeneralizationMassimiliano Mancini, Samuel Rota Bulò , Barbara Caputo , and 1 more authorIEEE Robotics and Automation Letters, Jul 2018
Robust Place Categorization With Deep Domain GeneralizationMassimiliano Mancini, Samuel Rota Bulò , Barbara Caputo , and 1 more authorIEEE Robotics and Automation Letters, Jul 2018Traditional place categorization approaches in robot vision assume that training and test images have similar visual appearance. Therefore, any seasonal, illumination and environmental changes typically lead to severe degradation in performance. To cope with this problem, recent works have proposed to adopt domain adaptation techniques. While effective, these methods assume that some prior information about the scenario where the robot will operate is available at training time. Unfortunately, in many cases this assumption does not hold, as we often do not know where a robot will be deployed. To overcome this issue, in this paper we present an approach which aims at learning classification models able to generalize to unseen scenarios. Specifically, we propose a novel deep learning framework for domain generalization. Our method develops from the intuition that, given a set of different classification models associated to known domains (e.g. corresponding to multiple environments, robots), the best model for a new sample in the novel domain can be computed directly at test time by optimally combining the known models. To implement our idea, we exploit recent advances in deep domain adaptation and design a Convolutional Neural Network architecture with novel layers performing a weighted version of Batch Normalization. Our experiments, conducted on three common datasets for robot place categorization, confirm the validity of our contribution.
@article{mancini2018robust, author = {Mancini, Massimiliano and Bulò, Samuel Rota and Caputo, Barbara and Ricci, Elisa}, journal = {IEEE Robotics and Automation Letters}, title = {Robust Place Categorization With Deep Domain Generalization}, year = {2018}, volume = {3}, number = {3}, pages = {2093-2100}, doi = {10.1109/LRA.2018.2809700}, month = jul, } -
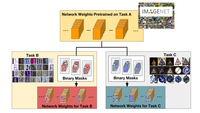 Adding New Tasks to a Single Network with Weight Transformations using Binary MasksMassimilano Mancini , Elisa Ricci , Barbara Caputo , and 1 more authorIn European Conference on Computer Vision (ECCV) Workshops , Sep 2018
Adding New Tasks to a Single Network with Weight Transformations using Binary MasksMassimilano Mancini , Elisa Ricci , Barbara Caputo , and 1 more authorIn European Conference on Computer Vision (ECCV) Workshops , Sep 2018Visual recognition algorithms are required today to exhibit adaptive abilities. Given a deep model trained on a specific, given task, it would be highly desirable to be able to adapt incrementally to new tasks, preserving scalability as the number of new tasks increases, while at the same time avoiding catastrophic forgetting issues. Recent work has shown that masking the internal weights of a given original conv-net through learned binary variables is a promising strategy. We build upon this intuition and take into account more elaborated affine transformations of the convolutional weights that include learned binary masks. We show that with our generalization it is possible to achieve significantly higher levels of adaptation to new tasks, enabling the approach to compete with fine tuning strategies by requiring slightly more than 1 bit per network parameter per additional task. Experiments on two popular benchmarks showcase the power of our approach, that achieves the new state of the art on the Visual Decathlon Challenge.
@inproceedings{mancini2018adding, author = {Mancini, Massimilano and Ricci, Elisa and Caputo, Barbara and Rota Bulò, Samuel}, title = {Adding New Tasks to a Single Network with Weight Transformations using Binary Masks}, booktitle = {European Conference on Computer Vision (ECCV) Workshops}, year = {2018}, month = sep, }




2017
-
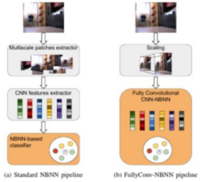 Learning Deep NBNN Representations for Robust Place CategorizationMassimiliano Mancini, Samuel Rota Bulò , Elisa Ricci , and 1 more authorIEEE Robotics and Automation Letters, Jul 2017
Learning Deep NBNN Representations for Robust Place CategorizationMassimiliano Mancini, Samuel Rota Bulò , Elisa Ricci , and 1 more authorIEEE Robotics and Automation Letters, Jul 2017This paper presents an approach for semantic place categorization using data obtained from RGB cameras. Previous studies on visual place recognition and classification have shown that, by considering features derived from pre-trained Convolutional Neural Networks (CNNs) in combination with part-based classification models, high recognition accuracy can be achieved, even in presence of occlusions and severe viewpoint changes. Inspired by these works, we propose to exploit local deep representations, representing images as set of regions applying a Naïve Bayes Nearest Neighbor (NBNN) model for image classification. As opposed to previous methods where CNNs are merely used as feature extractors, our approach seamlessly integrates the NBNN model into a fully-convolutional neural network. Experimental results show that the proposed algorithm outperforms previous methods based on pre-trained CNN models and that, when employed in challenging robot place recognition tasks, it is robust to occlusions, environmental and sensor changes.
@article{mancini2018learning, author = {Mancini, Massimiliano and Bulò, Samuel Rota and Ricci, Elisa and Caputo, Barbara}, journal = {IEEE Robotics and Automation Letters}, title = {Learning Deep NBNN Representations for Robust Place Categorization}, year = {2017}, volume = {2}, number = {3}, pages = {1794-1801}, doi = {10.1109/LRA.2017.2705282}, month = jul, } -
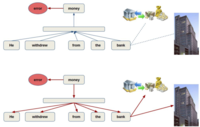 Embedding Words and Senses Together via Joint Knowledge-Enhanced TrainingMassimiliano Mancini, Jose Camacho-Collados , Ignacio Iacobacci , and 1 more authorIn Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017) , Jul 2017
Embedding Words and Senses Together via Joint Knowledge-Enhanced TrainingMassimiliano Mancini, Jose Camacho-Collados , Ignacio Iacobacci , and 1 more authorIn Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017) , Jul 2017Word embeddings are widely used in Natural Language Processing, mainly due to their success in capturing semantic information from massive corpora. However, their creation process does not allow the different meanings of a word to be automatically separated, as it conflates them into a single vector. We address this issue by proposing a new model which learns word and sense embeddings jointly. Our model exploits large corpora and knowledge from semantic networks in order to produce a unified vector space of word and sense embeddings. We evaluate the main features of our approach both qualitatively and quantitatively in a variety of tasks, highlighting the advantages of the proposed method in comparison to state-of-the-art word- and sense-based models.
@inproceedings{mancini2017embedding, title = {Embedding Words and Senses Together via Joint Knowledge-Enhanced Training}, author = {Mancini, Massimiliano and Camacho-Collados, Jose and Iacobacci, Ignacio and Navigli, Roberto}, booktitle = {Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017)}, pages = {100--111}, year = {2017}, }

